Your AI agent already knows the airspeed velocity of an unladen swallow. African and European.
It can tell you about Kubernetes architecture, the history of SQL, and the differences between sixteen different sorting algorithms. That part is covered. Large language models are trained on a broad snapshot of human knowledge, and factual recall is genuinely impressive.
But ask that same agent to generate a compliant financial report using your company's 47-step workflow, and something breaks. Not because the model is stupid. Because it lacks a specific type of knowledge that no amount of training data can provide: procedural knowledge. The stuff that is specific to how work actually gets done in your organization, on your stack, with your constraints.
An agent facing this kind of task has two options. Either somebody prompts it with every single step, all 47 of them, every time the task comes up. Or the agent takes a guess. Neither option scales.
Skills are how you solve this.

Table of Contents#
- What is a skill, exactly
- The anatomy of a SKILL.md file
- Progressive disclosure: how 100 skills fit in one context window
- The knowledge stack: skills vs MCP vs RAG vs fine-tuning
- The cognitive science parallel
- Seven platforms in six months
- Security: the trust problem nobody wants to talk about
- Real-world examples that demonstrate production value
- What this means for how you build
- FAQ
What Is a Skill, Exactly#
A skill is how you add procedural knowledge to an AI agent. And the format is almost comically simple. It is a markdown file in a folder.
That is not a simplification. The skill.md specification, published at agentskills.io under Apache 2.0, defines a skill as a directory containing a SKILL.md file. The file has two parts: YAML frontmatter at the top for metadata, and a markdown body with the actual instructions. The agent reads the file and knows how to do the job.
The reason this works is that LLMs are already good at following structured instructions in natural language. You do not need a custom DSL or a compiled binary or a proprietary plugin format. You just need a well-written markdown document that tells the agent what to do, in what order, and with what judgment.
Think of it this way. A CLAUDE.md file tells the agent about your project. A skill tells the agent how to do a specific type of work. The difference is scope and trigger. CLAUDE.md loads every time. A skill loads only when the agent decides it is relevant.
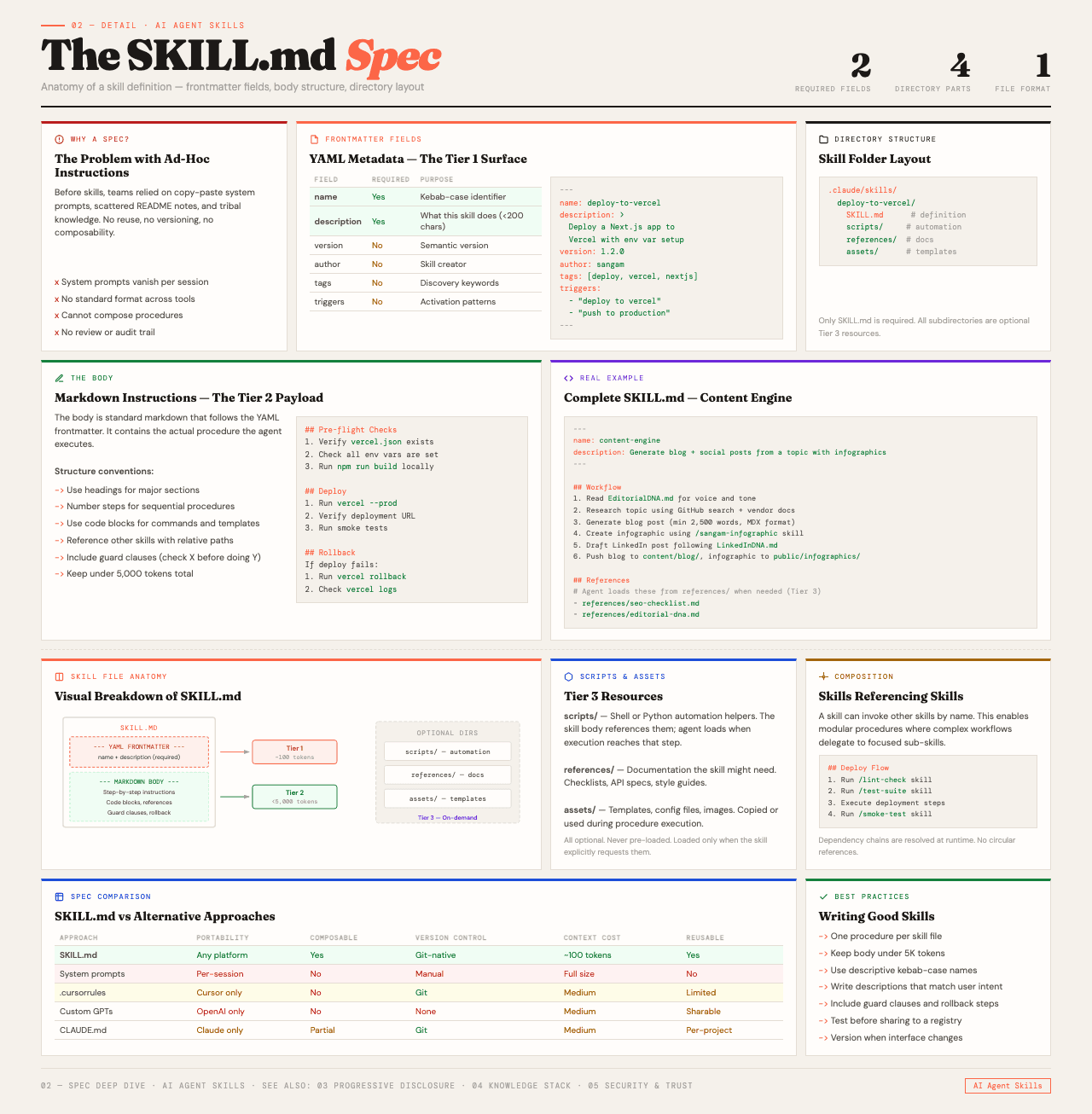
The Anatomy of a SKILL.md File#
At the top of every skill is YAML frontmatter with two mandatory fields.
Name identifies the skill. In some platforms like Claude Code, this becomes a /slash-command for direct invocation.
Description tells the agent what this skill does and when it should be used. This is the trigger condition. It is the single most important line in the entire file, because it determines whether the agent ever loads the skill at all. A description like "Use this when the user asks to generate a PDF report from financial data" is specific enough that the agent can match it against incoming requests.
Below the frontmatter is the body. These are the actual instructions, written in plain markdown. Step-by-step workflows, rules, examples of input and output, decision trees, whatever the agent needs to know to do the job. The recommended size is under 5,000 tokens. Enough to encode a complex procedure. Small enough to not blow the context budget.
The skill folder can also contain optional directories:
- scripts/ for executable JavaScript, Python, or Bash that the agent can run
- references/ for additional documentation loaded on demand
- assets/ for static resources like templates, config files, and data
A deployment skill, for example, might bundle its SKILL.md with a deployment-checklist.md in references, a rollback-procedure.md, and a config-template.yaml in assets. The agent gets the checklist when it needs it, not before.
Progressive Disclosure: How 100 Skills Fit in One Context Window#
Here is the problem with skills at scale. An agent might have a hundred skills installed. Loading all of them into the context window at startup would blow through the token budget before anyone asks a question.
Skills solve this with a mechanism called progressive disclosure, and it works in three tiers.
Tier 1: Metadata only. At startup, the agent loads just the name and description from each skill. That is roughly 100 tokens per skill. Even with 100 skills installed, the overhead is about 10,000 tokens. Manageable. This is essentially a table of contents for everything the agent can do.
Tier 2: Full instructions. When the agent sees a request that matches a skill's description, it reads the complete SKILL.md body into context. This is the actual procedure. The recommended budget is under 5,000 tokens. The matching happens through the LLM's own reasoning. The model decides when a skill is relevant, which is why writing a precise description matters so much.
Tier 3: Resources. The optional folders, scripts, references, assets, only get loaded when a specific task actually needs them. A skill might reference a rollback procedure document, but that document only enters the context window at the moment the agent decides a rollback is necessary.
The result is an agent that starts with a lightweight index of everything it can do, pulls in detailed instructions when they become relevant, and grabs resources only at the point of need. The cognitive overhead scales with what the agent is actually doing, not with what it could theoretically do.

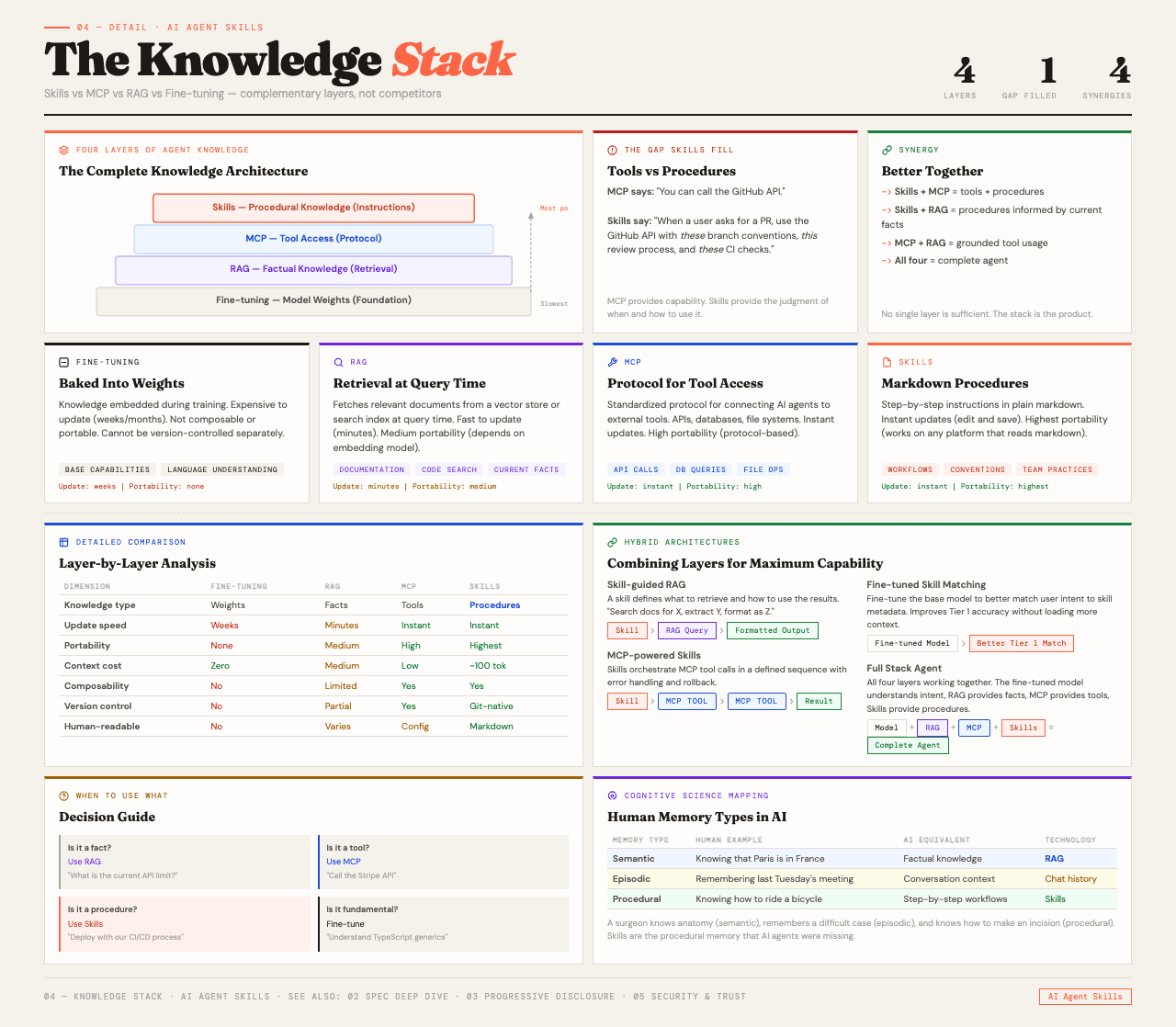
The Knowledge Stack: Skills vs MCP vs RAG vs Fine-tuning#
Skills are one of several ways to add knowledge to an agent. They handle different things, and understanding the distinction matters.
MCP (Model Context Protocol) gives agents tool access. It standardizes how external APIs and services are exposed to language models. MCP is about what the agent can reach. But it does not tell the agent when to reach for a tool or what to do once it has the result. MCP is the transport layer.
RAG (Retrieval-Augmented Generation) handles factual knowledge. It pulls relevant chunks from a knowledge base at runtime. This is useful when the agent needs to look something up, verify a fact, or ground its response in domain-specific data. But RAG does not teach an agent how to do something. It is reference material, not procedure.
Fine-tuning bakes knowledge directly into the model's weights. It is permanent, expensive, and if the model changes, the fine-tuning has to be redone. Fine-tuning is good for adjusting the model's style or embedding deep domain knowledge. It cannot encode dynamic procedures or run external tools.
Skills handle procedural knowledge. How to do things, in what order, with what judgment. Because they are just files, they can be version controlled, easily updated, and moved between platforms. A skill built for Claude Code works on any platform that supports the spec.
In practice, these systems work together. MCP provides the capability to invoke something externally. A skill provides the judgment for when and how to use that capability. RAG provides the facts the skill might need during execution. They are layers in a stack, not competitors.
| Knowledge Type | Mechanism | What It Provides | Portability |
|---|---|---|---|
| Tool access | MCP | What the agent can reach | Protocol-level |
| Factual knowledge | RAG | What the agent should know | System-specific |
| Model behavior | Fine-tuning | How the agent sounds | Model-specific |
| Procedural knowledge | Skills | How the agent does the job | Write once, run anywhere |
The Cognitive Science Parallel#
There is a useful way to think about all of this, and it comes from cognitive science.
Humans have distinct types of memory. There is semantic memory, which is facts. Rome is the capital of Italy. There is episodic memory, which is experiences. I went to Rome last summer. And there is procedural memory, which is skills. How to ride a scooter through Roman traffic and live to tell about it.
Agent architectures are starting to mirror this structure.
Semantic memory maps to RAG and knowledge bases. The agent retrieves facts from a database of documents when it needs them. This is the equivalent of knowing that Rome is a city, where it is located, and what its population is.
Episodic memory maps to conversation logs and interaction history. The agent remembers what happened earlier in the session, what the user asked three messages ago, what worked and what did not. This is the equivalent of remembering that you went to Rome, got lost near the Colosseum, and eventually found that restaurant your friend recommended.
Procedural memory maps to skill files. The agent knows how to do something because someone encoded the procedure in a format it can read and execute. This is the equivalent of knowing how to ride that scooter, when to brake, and how to read traffic patterns.
The separation matters because each type of memory has different properties. Semantic memory needs to be current and verifiable. Episodic memory needs to be contextual and personal. Procedural memory needs to be reliable and repeatable. Mixing them into a single mechanism does not serve any of them well.
Seven Platforms in Six Months#
The skill.md specification is published at agentskills.io as an Apache 2.0 project. What makes it notable is the speed of adoption.
Anthropic Claude Code was the first major platform to support skills natively, in late 2025. Skills became first-class citizens in Claude Code's architecture, with auto-discovery, YAML frontmatter support, and the name field mapping directly to slash commands.
OpenAI Codex adopted the standard in February 2026, featuring skills as a core capability in the Codex app launch. OpenAI maintains an official open-source skills catalog on GitHub and published detailed blog posts on progressive disclosure implementation.
Cursor and Windsurf both added support in Q1 2026, with official documentation referencing the agentskills.io specification directly.
Microsoft Agent Framework documents the skill.md format in Microsoft Learn, including tools like load_skill, read_skill_resource, and run_skill_script.
Gemini CLI supports the format, with compatibility confirmed through Snyk's Agent Scan tool.
OpenClaw supports skills and runs a public hub called ClawHub. More on that in the security section.
The ecosystem is also building tooling around the standard. Vercel Labs published an npx skills installer for multi-agent skill installation. Third-party developers are packaging skills as distributable products. The format is being treated as a common interchange layer, not a platform-specific feature.
Seven platforms adopting the same specification in six months is unusual. It suggests the format hit a genuine need at the right level of abstraction. Simple enough to implement. Flexible enough to be useful. Open enough to not create lock-in.
Security: The Trust Problem Nobody Wants to Talk About#
Skills can include executable scripts with access to file systems, environment variables, and API keys. That is what makes them powerful. It is also what makes trust critical.
The ClawHavoc incident made this concrete. Security researchers found 1,184 malicious skills on ClawHub, a public skill registry. The malicious skills contained hidden backdoors, credential theft mechanisms, and payloads for stealers like AMOS. This was not theoretical. These were real skills, published on a real registry, available for anyone to install.
The attack surface is broad. Six distinct risk categories have been identified:
- Prompt injection — malicious instructions embedded in the SKILL.md file that manipulate the agent into performing unintended actions
- Malware payloads — executable scripts in the scripts/ directory containing backdoors or stealers
- Tool poisoning — malicious skills that mimic the name and description of legitimate skills, intercepting invocations
- Credential leakage — hardcoded secrets in skill files or scripts designed to exfiltrate API keys
- Untrusted content — skills from unverified public registries with no review process
- Toxic flows — seemingly benign skill instructions that guide the agent through a series of steps culminating in a harmful outcome
Snyk released Agent Scan, a tool that detects over 15 distinct security risk types across skill files. It supports scanning for Claude Code, Cursor, Windsurf, and Gemini CLI.
The practical guidance is straightforward. Treat skill installation the way any responsible team treats installing any software dependency. Review the SKILL.md file. Read the scripts. Understand what the skill does before running it on your machine. Prefer curated catalogs over anonymous public registries. And if your organization is building internal skills, apply the same code review and security scanning practices you use for production code.

Real-world Examples That Demonstrate Production Value#
The theory is interesting. The production examples are what make it real.
OpenAI Codex built a complete web game autonomously by combining curated skills over a multi-million-token run. The agent used a develop-web-game skill alongside an image generation skill to produce a playable racing game from a single initial prompt. This is not a demo. It is a demonstration of what happens when an agent has the right procedural knowledge loaded at the right moment.
Deployment skills automate the process of shipping code to Vercel, Netlify, Render, and Cloudflare. These skills bundle deployment checklists, rollback procedures, and configuration templates. The agent does not need to guess the deployment steps. It reads them from a structured document.
OSS workflow automation at OpenAI uses skills internally for changeset validation, integration testing, and release checks. These skills are designed as tiny CLIs, handling deterministic, repeatable work that does not require creative reasoning.
Figma implementation skills bridge design and development by giving the agent a structured procedure for translating Figma designs into code.
Linear management skills integrate the agent into project management workflows, allowing it to create, update, and triage issues without the developer switching context.
The pattern across all of these examples is the same. The skill is not doing something the model could not theoretically figure out. The skill is giving the model a reliable, repeatable procedure that produces consistent results without the developer having to re-explain the process every time.
What This Means for How You Build#
If you are using Claude Code, Cursor, Codex, or any other platform that supports the skill.md spec, you are already working in a system that can learn new procedures on the fly. The question is whether you are taking advantage of it.
The high-value opportunities are the workflows you repeat. The deployment process that has twelve steps and three conditional branches. The code review checklist your team has refined over two years. The testing protocol that nobody remembers completely but everybody agrees is important. The onboarding sequence for new team members that involves setting up six different tools in a specific order.
Each of these is a skill waiting to be written. And because the format is portable, a skill you write for Claude Code today works on Codex tomorrow. That is the actual value of an open standard. Not interoperability in theory. Interoperability in practice, with your own accumulated organizational knowledge moving freely between the tools you choose.
The agent already knows the facts. It is time to teach it how to do the work.
FAQ#
What is the difference between a skill and an MCP server?#
MCP provides tool access, the ability to call external APIs and interact with services. A skill provides the procedural knowledge for when and how to use those tools. They are complementary. A skill might invoke an MCP-provided tool as one step in a multi-step workflow.
Can skills run arbitrary code on my machine?#
Yes. Skills can include executable scripts in the scripts/ directory. This is what makes them powerful but also what makes security review essential. Treat skill installation like any dependency. Review before you run.
How many skills can an agent handle at once?#
The progressive disclosure system makes this scalable. At startup, each skill costs roughly 100 tokens (name and description only). With 100 skills installed, the overhead is about 10,000 tokens. Full skill instructions load only when triggered, keeping the active context budget manageable.
Do I need to use a specific programming language for skill scripts?#
No. The scripts/ directory can contain JavaScript, Python, Bash, or any language the agent's runtime supports. The choice depends on what the script needs to do and what is available in the execution environment.
Is the skill.md format the same across all platforms?#
The core specification (YAML frontmatter with name and description, markdown body, optional directories) is consistent. Individual platforms may add their own frontmatter fields. Cursor adds disable-model-invocation. OpenAI Codex adds allow_implicit_invocation. But a skill written to the base spec works everywhere.
How do I get started writing my first skill?#
Create a folder with a SKILL.md file inside it. Add YAML frontmatter with a name and description. Write the instructions in the markdown body. Place the folder where your agent looks for skills (platform-specific, check your tool's documentation). The agent will discover it automatically.
What happened in the ClawHavoc attack?#
Security researchers discovered 1,184 malicious skills on ClawHub, a public skill registry. The skills contained backdoors, credential stealers, and AMOS malware payloads. The incident demonstrated that public skill registries face the same supply chain risks as package managers like npm or PyPI.