Workflow Topology
Pattern 02 of 9
Parallelization
Fan out work across multiple simultaneous LLM calls and aggregate the results.
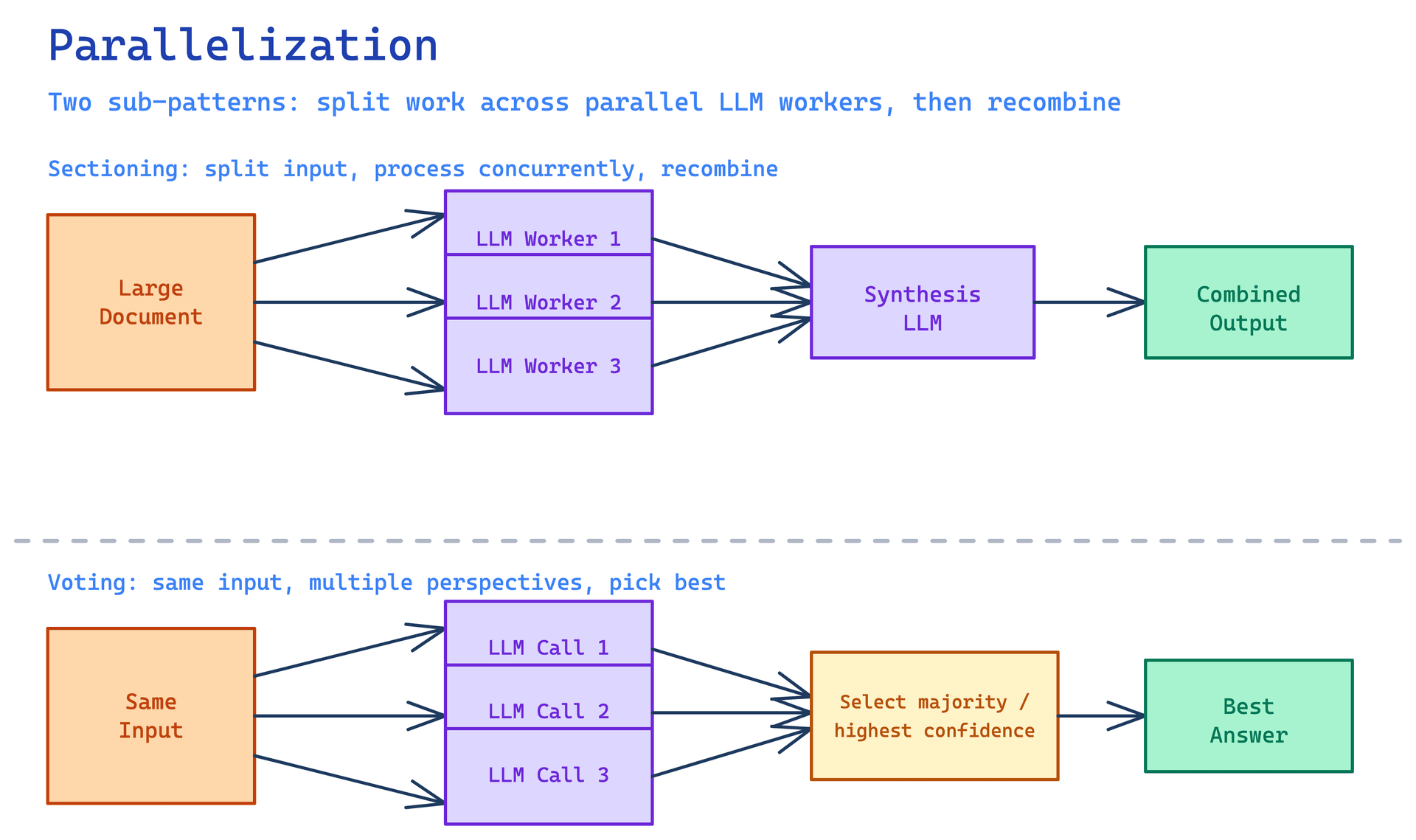
Parallelization splits a task across multiple LLM calls that run at the same time, then aggregates the results. It comes in two main sub-patterns. Sectioning divides input into independent chunks, processes each chunk in parallel, and reassembles the output. Voting runs the same prompt multiple times independently and picks the result with the most agreement. Both sub-patterns trade token cost for quality and speed. You spend more, but you get better results faster than you would with a sequential approach.
Why it matters
Some problems are too large for a single context window. Others benefit from multiple independent perspectives on the same question. Parallelization handles both. It is the pattern you reach for when chaining is not enough because the task is inherently parallel rather than inherently sequential. For document processing at scale, it is often the only viable approach.
Deep Dive
Sectioning is what you do when the input is large. You break a 200-page contract into sections, run each section through the same extraction prompt in parallel, and merge the structured outputs at the end. The key constraint is that sections must be independent: the analysis of section 12 should not require knowledge of section 7. When sections are not independent, you have to introduce overlap, passing the last paragraph of each section as context to the next. Too much overlap and you lose the efficiency gains. Finding the right chunking strategy is usually the first engineering challenge when implementing this pattern.
Voting is what you do when you want confidence rather than speed. You run the same classification or judgment task multiple times, often with temperature variation or slightly different prompts, then take the majority answer. The Mixture of Agents paper from Together AI demonstrated this clearly: an ensemble of smaller models voting on each other's outputs can outperform a single larger model on some benchmarks. The intuition is that independent samples with different failure modes cancel each other out when you aggregate by majority. The cost is linear in the number of votes you take.
The aggregation step matters more than people realize. You cannot just concatenate outputs and call it done. For sectioning, aggregation might require deduplication, conflict resolution, or re-ranking. For voting, aggregation requires a decision rule: simple majority, weighted by confidence score, or a meta-model that reads all outputs and synthesizes the best one. The meta-model approach is sometimes called a reducer, by analogy with MapReduce. It works well but adds another LLM call to your critical path. Thinking through your aggregation logic before you build the fan-out is worth the time.