I shipped a working prototype in two days that would have taken two weeks before Claude Code. I was proud of myself for exactly 48 hours. Then the API bill arrived.
Not a catastrophic bill. Just enough to make me do the math forward. If this thing runs in production at any real scale, if agents are making dozens of calls per session, if I am using the top model because the cheaper ones make mistakes that cost more than the price difference, the numbers compound fast.
That gap, the collapse in build cost against the rise in run cost, is the central tension in agentic development right now. And it turns out there is a specific set of problems causing it, and a specific solution that actually works.
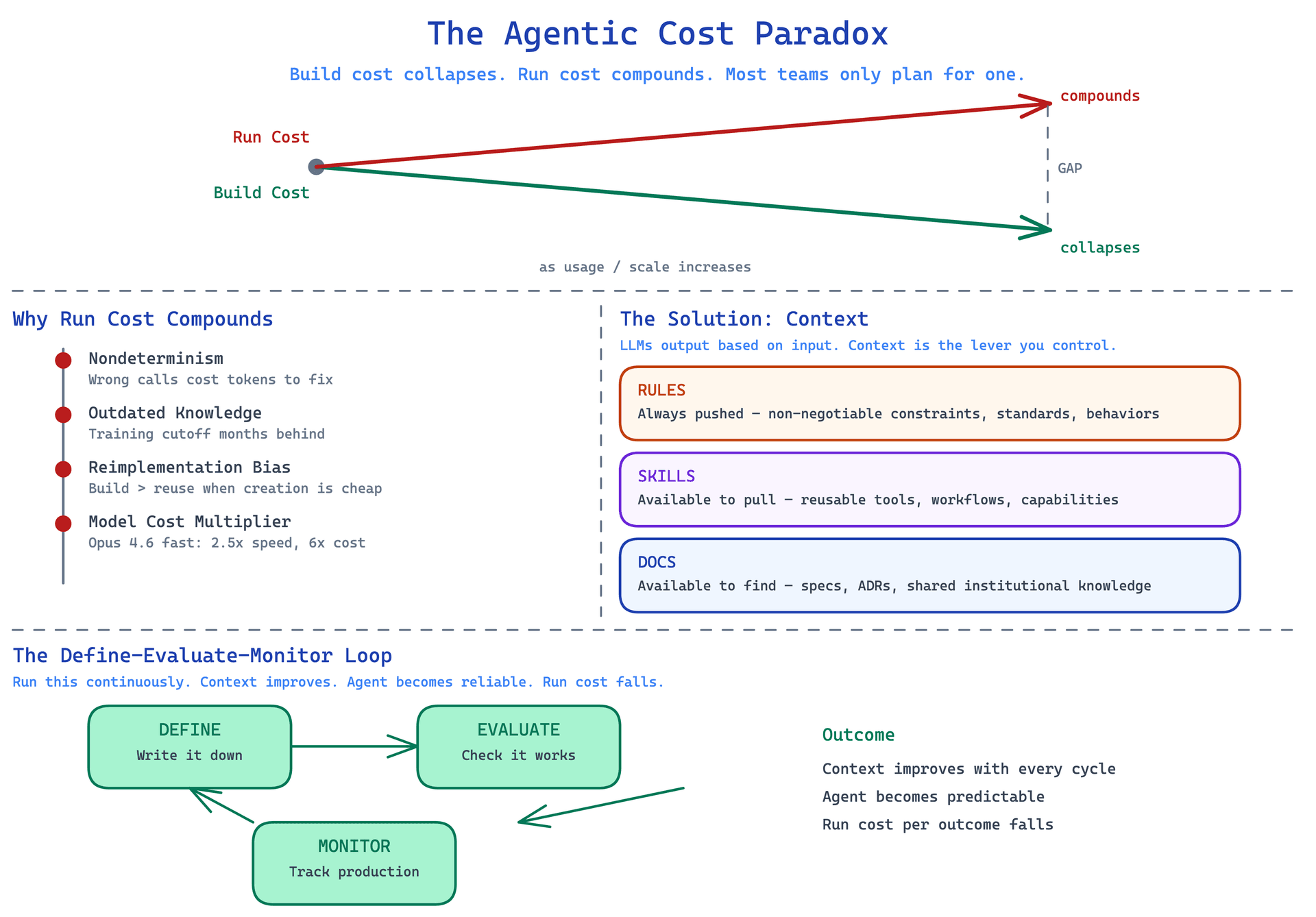
Table of Contents#
- The cost paradox no one warns you about
- Four challenges that make agentic development expensive
- The hammer you actually have: context
- Three types of context
- The define-evaluate-monitor loop
- What this looks like in practice
- FAQ
The Cost Paradox No One Warns You About#
The reason building agentic apps feels so different now is that the cost structure of software has inverted.
Before AI tools, the expensive part of building software was human time. Design decisions took meetings. Implementation took weeks. QA took cycles. Every hour of developer time had a price tag, and that price tag was the limiting constraint on what you could attempt.
Agentic development collapses that part of the equation. You can build things in a day that used to take a sprint. The human effort part of the cost curve has genuinely fallen.
But something else has happened at the same time. The run cost has risen. And unlike human time, which you pay for upfront and stop paying once the feature ships, inference costs follow your usage. Every agent call, every token in, every token out. Claude Opus 4.6 with fast mode is 2.5 times faster at six times the cost. If you are building anything that uses the top model with any frequency, you feel it.
The instinct is to switch to a cheaper model. That sometimes works. But the cheaper model makes more mistakes, and mistakes in agentic systems are not free. An agent that goes in the wrong direction for five minutes and then has to be corrected has consumed more tokens than the better model would have, plus your time, plus whatever it did wrong. The economic case for the top model is often stronger than it first appears.
This is the paradox. Build cost goes down. Run cost goes up. The people who are succeeding with agentic development right now have figured out how to manage the run cost without sacrificing the capability that makes the build cost cheap.
The way they do it is context.
Four Challenges That Make Agentic Development Expensive#
Before getting to the solution, it helps to be precise about what the actual problems are. There are four, and they interact with each other.
Nondeterminism. LLMs are not functions. You cannot call them with the same inputs twice and expect the same output. This is not exactly a bug, but it is a real challenge for anyone building systems that need to behave predictably. A human engineer who makes the same code change ten times will get the same result. An agent doing the same task ten times will produce ten variations. Some will be good. Some will not. You need a way to evaluate which is which, and every failed attempt costs tokens.
Outdated knowledge. Every model you use today was trained at least a few months ago. Usually longer. By the time you are calling any frontier model in production, its internal knowledge is already behind. New packages, updated APIs, recent framework changes, security advisories from last month. The agent does not know about them. Its confidence about things it does not know is indistinguishable from its confidence about things it does. You have to supply current information as part of the context, or the agent reasons from stale data and produces expensive wrong answers.
Bias toward reimplementation. Because creating software has gotten so cheap, agents have a tendency to build new things rather than find and reuse existing things. It is genuinely easier for an agent to write a new utility function than to search a codebase for one that already exists and understand its interface. The cost of creation has fallen enough that reuse is no longer the obvious default. This has real implications for codebase health over time that compound in ways you do not notice until the codebase is a mess.
The cheap-to-build, expensive-to-run gap. This one deserves its own entry because it is not just a financial observation. It changes what you optimize for when designing systems. When the constraint was human time, you optimized for developer experience and ship speed. Now the runtime constraint is inference cost, and you optimize for token efficiency, context size, and call frequency. These are different skills. Most teams that learned to build software have not yet learned to think this way.
The Hammer You Actually Have: Context#
The solution to all four challenges is the same thing: context management.
This sounds almost too simple. But the insight is correct. LLMs are, at the most fundamental level, machines that calculate outputs based on what you pass to them. Every token in the context window shapes the probability distribution of what comes out. If you want the agent to behave differently, the primary tool available to you is changing what it sees.
The analogy that makes this concrete is team management. When you manage a team of people, your primary tools are communication and incentives. You cannot directly control what your team members do. You can tell them what to do, give them the information they need, structure their environment, and create feedback loops that reward the behavior you want. What you cannot do is reach into their minds and adjust their decisions directly.
Agents work the same way. You cannot reprogram the model. You can change the context it receives. That context, managed well, is how you get consistent, useful, cost-efficient behavior from nondeterministic systems.
The people building agentic apps that actually work in production are not finding better prompts. They are engineering better context.
Three Types of Context#
Not all context is the same. There are three distinct categories, and understanding the difference between them changes how you design your systems.
Rules are the things you push explicitly. These are the instructions the agent will always see, always apply, and should treat as constraints rather than suggestions. Your CLAUDE.md file is full of rules. The company coding standards, the security requirements, the architectural decisions that are not up for debate. Rules work best when they are concise, specific, and non-contradictory. A 20-page document of rules is worse than a tight list of 15. The more words you use to describe a rule, the harder it is for the model to weight it correctly against everything else in the context window.
Skills are things you make available rather than push. You are not including them in every interaction. You are signaling that they exist and can be pulled in when relevant. A skill is a tool, a workflow, a reusable capability. The agent can invoke it when the task calls for it. This is how you give agents breadth without bloating every context window. If you have a skill for running database migrations, you do not need to include the full migration instructions in every coding session. You surface the skill, and the agent pulls it when relevant.
Docs are information available for retrieval. Technical documentation, product specs, architecture decision records, the accumulated institutional knowledge that would otherwise live only in engineers' heads. Docs work differently from rules and skills because the agent has to actively find them rather than receiving them automatically. This means they need to be discoverable: indexed, named in ways that match how the agent will search, and accurate enough that finding them is better than not finding them.
The practical implication of these three categories is that you need to be deliberate about which type of context you are using for which purpose. Rules for non-negotiable constraints. Skills for reusable capabilities. Docs for information the agent needs to look up. Mixing these up is one of the most common ways context management breaks down.
The Five Pillars of Agentic Engineering covers context engineering as a pillar in its own right, with more detail on how CLAUDE.md files and skills work together as a system.
The Define-Evaluate-Monitor Loop#
Context management is not a one-time configuration problem. It is an ongoing loop. The three steps are define, evaluate, and monitor, and they feed each other.
Define is the hardest step. You have to articulate what you want the agent to do. Not in vague terms. Specifically. What is the desired behavior in this specific situation? What does success look like versus failure? What are the edge cases?
This is harder than it sounds. Most teams skip it because it feels like overhead. They know what they want, roughly, and they expect the agent to figure out the details. Sometimes that works. When it does not, the failure mode is not a crash or an error. It is an agent that does something technically plausible but wrong, and you only find out when a user complains or you happen to review the output.
Writing down what you want forces clarity that you did not know was missing. It surfaces disagreements between team members that would otherwise show up as inconsistent agent behavior. It creates a shared reference that every subsequent agent run can be evaluated against. The act of writing the spec is often where you discover the spec is not yet a spec.
Evaluate is how you find out whether your definitions are working. The closest analogy is testing. You write down what success looks like, then you check whether the agent produces it. The difference from traditional testing is that you are testing nondeterministic outputs, so you need evaluation criteria that can tolerate variation in form while being clear about variation in substance.
Format matters here in ways that are not immediately obvious. A dense paragraph of instructions evaluates differently than a structured list of criteria. Different models weight these formats differently. Some models follow numbered instructions more reliably than bulleted ones. Some models perform better with examples than with abstract descriptions. Evaluation helps you find out which format works for your specific use case and your specific model. You cannot assume what works for one will work for another.
Monitor is the DevOps layer for agentic systems. Traditional software systems are deterministic, but we still run them with monitoring, alerting, and observability tooling because production is unpredictable. Agentic systems are nondeterministic from the start, which means monitoring is not optional, it is foundational. You need to know how often the agent is succeeding, where it is failing, what the failure modes look like, and whether changes to your context definitions are making things better or worse.
The instrumentation for agentic monitoring looks different from traditional application monitoring. You are not just tracking latency and error rates. You are tracking output quality, task completion rates, cost per successful outcome, and the frequency of different failure modes. Building this observability in from the start is one of the things that separates teams that scale agentic systems from teams that hit a wall and cannot figure out why.
The engineering patterns that make these systems maintainable are covered in more depth in Building Production-Ready Multi-Agent Systems, particularly around state management and structured error handling.
What This Looks Like in Practice#
The teams I have seen figure this out are not doing anything magical. They are being disciplined about a few specific things.
They write down what they want before they build it. Not after, when the agent has already made ten decisions they disagree with and they are trying to reverse-engineer why. Before. The specs they write are imperfect, but the act of writing them forces the kind of clarity that context management requires. Imperfect specs that exist are better than perfect specs that do not.
They run evaluation on a schedule. Not just when something seems wrong. Regular, structured evaluation runs that tell them whether the agent's behavior on a defined set of scenarios has changed since the last time they looked. This sounds like extra work. It prevents the specific type of slow drift where the agent gets slightly worse over time and nobody notices until users do.
They treat token cost as a first-class engineering metric. Not an afterthought, not something to optimize later. Cost per successful outcome is something they measure and track from the beginning. This changes how they design context. A rule that saves two tokens per call sounds trivial. At a million calls, it is not.
They build incrementally rather than comprehensively. The first version of their context is not the final version. They define something, evaluate it, see where it fails, and refine the definition. The loop runs continuously. The context gets better. The agent behavior gets more reliable. The run cost comes down as the agent stops doing expensive things that turn out to be wrong.
Before You Run 10 Claude Agents in Parallel covers the practical progression from single-agent to multi-agent setups, which is where cost management discipline becomes most important. The mistakes that are annoying at one agent become expensive at ten.
The cost paradox in agentic development is real. Build cost is down. Run cost is up. But the paradox resolves when you treat context management as the engineering discipline it actually is. Define. Evaluate. Monitor. Repeat. The teams that do this build things that scale. The teams that do not keep getting surprised by bills.
FAQ#
Why do agentic apps cost so little to build?#
Agentic development dramatically reduces the human time required to write, debug, and ship software. Tasks that previously required days of engineering work can now be completed in hours with AI coding agents. The primary cost of software development has historically been human labor, and that cost has fallen significantly for teams using agentic tools effectively.
Why do agentic apps cost so much to run?#
Each agent action requires one or more API calls to a large language model, and inference costs add up quickly at scale. Using top-tier models compounds this further: Claude Opus 4.6 with fast mode is 2.5 times faster at six times the cost of the standard mode. Because agent tasks often require multiple tool calls, reasoning steps, and validation passes, the token count per task can be substantial. At any meaningful usage volume, these costs become a significant operational expense.
What is context management in agentic development?#
Context management is the discipline of controlling what information an AI agent sees when it makes decisions. Because LLMs are stateless machines that calculate outputs based on inputs, the quality and precision of the context is the primary lever for controlling agent behavior. Context management includes deciding what rules to enforce, what skills to make available, and what documentation to provide for retrieval.
What are the three types of context for AI agents?#
Rules are instructions pushed explicitly into every interaction, covering non-negotiable constraints and required behaviors. Skills are reusable capabilities made available for agents to pull in when relevant, rather than being present in every context window. Docs are information available for retrieval, covering the institutional knowledge the agent might need to look up during a task. Each type is managed differently and serves a different purpose.
What is the define-evaluate-monitor loop?#
The define-evaluate-monitor loop is the core operational pattern for managing agentic systems over time. Define means articulating exactly what you want the agent to do in written, specific terms. Evaluate means checking whether the agent's actual output meets those definitions on a regular basis. Monitor means tracking agent performance in production continuously, similar to how DevOps teams monitor runtime systems. The three steps form a continuous improvement loop rather than a one-time setup.
How do you reduce the run cost of agentic apps?#
The most effective approaches are: writing concise, specific context definitions that reduce the number of correction cycles the agent needs; choosing the right model for each task rather than defaulting to the most powerful model for everything; designing agent workflows to minimize unnecessary tool calls; and using evaluation data to identify and eliminate the specific failure modes that cause the most expensive reruns. Cost per successful outcome is a more useful metric than raw token cost.
How is monitoring agentic systems different from traditional application monitoring?#
Traditional application monitoring tracks latency, error rates, and resource usage. Agentic system monitoring adds output quality tracking, task completion rates, cost per successful outcome, and failure mode frequency. Because agent behavior is nondeterministic, monitoring needs to capture whether the agent is doing the right thing, not just whether it is producing output without crashing.