There is a moment, usually late at night, when you stop pretending that what you are doing is engineering.
You have been in a conversation with Claude for three hours. The code works in the sense that it runs without crashing. But when you look at what got built, really look at it, you cannot trace a single architectural decision back to something intentional. The agent went in a direction. You followed. That is vibe coding.
I have been there. More times than I want to admit.
This past month, I started watching what the engineers I most respect are actually doing with AI tools. Not what they say they do. What they actually do. The pattern that emerged has a name: agentic engineering. And it is meaningfully different from vibe coding in ways that compound over time.
A Meta Staff Engineer recently published a video explaining the distinction through five pillars. I went through it twice and recognized almost every principle from my own trial-and-error with Claude Code. This is my attempt to synthesize what I learned, with context from my own experience building on top of it.
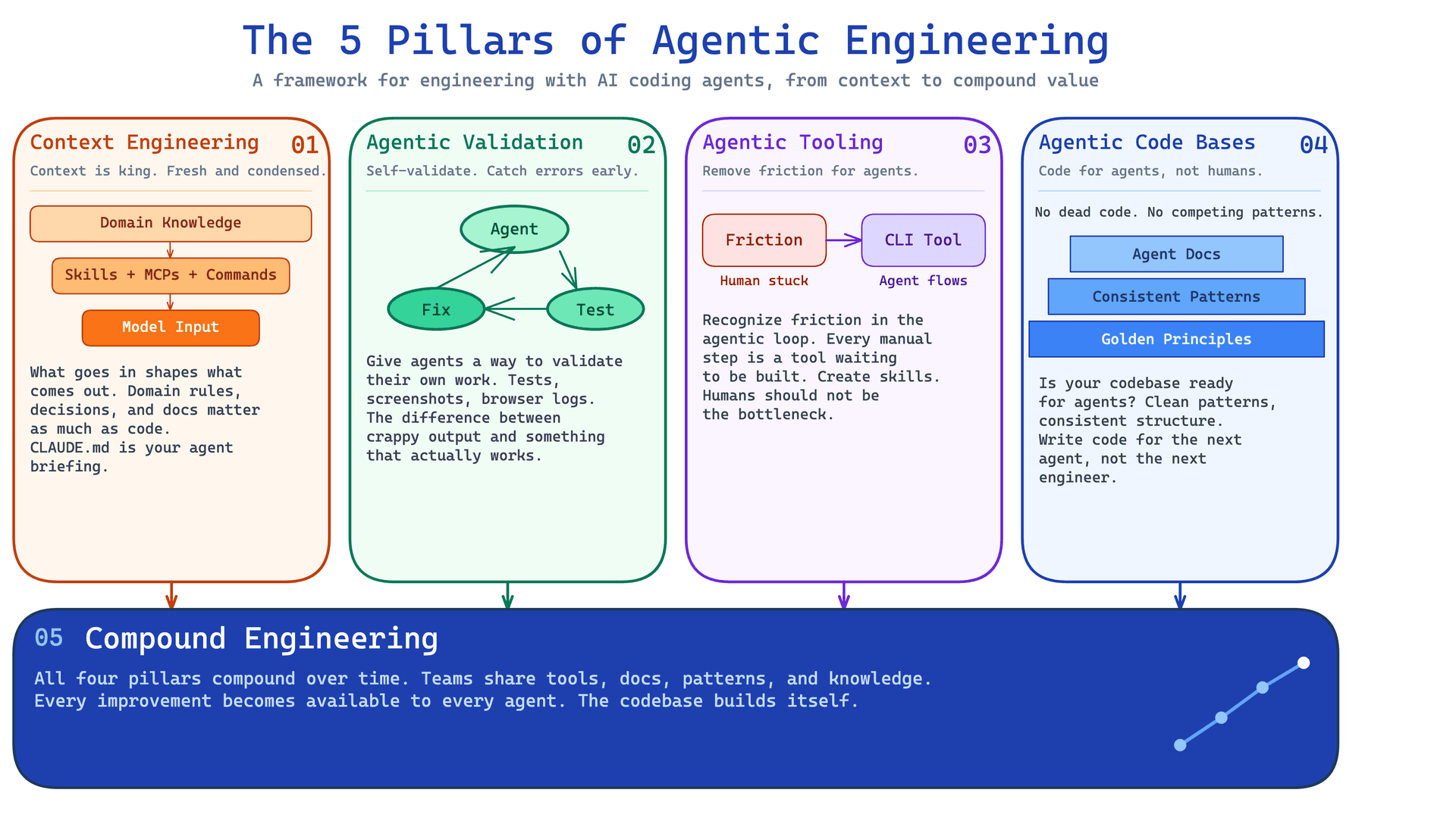
Table of Contents#
- Why agentic engineering is not vibe coding
- Pillar 1: Context Engineering
- Pillar 2: Agentic Validation
- Pillar 3: Agentic Tooling
- Pillar 4: Agentic Code Bases
- Pillar 5: Compound Engineering
- What this means in practice
- FAQ
Why Agentic Engineering Is Not Vibe Coding#
Andrej Karpathy recently wrote that what he does these days is not vibe coding but agentic engineering. He specifically called out the word "engineering" in that description, because it is engineering. There is system design. There is intent. There is a feedback loop you understand and can improve.
Peter Steinberger, who recently joined OpenAI, said something sharper: vibe coding is basically a slur now. His framing was agentic engineering "with a little star." The star matters because what he is describing involves real thought about architecture, real decisions about what the agent can and cannot do, and real engineering that holds together under pressure.
The difference I have felt most personally is this: with vibe coding, you are hoping the agent goes in the right direction. With agentic engineering, you have designed the conditions under which it can only go somewhere useful.
That design is what the five pillars describe.
Pillar 1: Context Engineering#
The first and most important pillar is also the simplest to state: garbage in, garbage out.
Context engineering is the practice of thinking carefully about what you feed the model. Not "more is better." The opposite, actually. The framing that stuck with me: context is best served fresh and condensed.
The reason this matters is that these models work probabilistically. Every token in the context window shapes the probability distribution of what comes out. If your context contains conflicting instructions, outdated information, or irrelevant noise, the agent will reflect that. Not always. Not predictably. But consistently enough that you will waste hours debugging outputs that are actually just symptoms of bad context.
What this looks like in practice: your CLAUDE.md file is not a dumping ground. It is a briefing document. Everything in it should be there because removing it would make the agent worse at its specific tasks. Skills and MCPs are context engineering tools. They let you inject focused, relevant information at the moment the agent needs it, rather than flooding the entire context window upfront.
OpenAI published an article about their internal Harness Engineering project that articulated something I had been feeling without being able to name. Their rule: if the domain knowledge does not exist in the codebase, it does not exist for the agents at all. Decisions from Slack threads, architectural choices made in a meeting two months ago, the reason a particular pattern was chosen over a simpler one. All of it is invisible to the agent unless you encode it somewhere the agent can read.
That is the job of context engineering. Not just configuration. Documentation of intent, written for a reader that is not human.
Pillar 2: Agentic Validation#
Boris Chen, the creator of Claude Code, described this pillar in a January post about his workflows. The observation was simple and it changed how I build: if you give an agent a way to validate its own work, the output gets dramatically better.
This sounds obvious. It is not obvious in practice.
The default workflow is: agent writes code, you run it, you find the bugs, you paste the error back in, the agent fixes it. You are the validation loop. You are also the bottleneck.
Agentic validation means engineering a feedback mechanism that the agent can use without you. For backend tasks, this is integration tests or unit tests that run automatically. For frontend work, it might be a headless browser that takes screenshots after each change. For mobile, the ADB simulator. The specific mechanism depends on your stack, and designing it well is where a lot of the interesting engineering happens right now.
The creative challenge is UI validation. Screenshots are imperfect. We do not yet have great video models in the agentic coding loop. But you can build domain-specific tools: navigation scripts that simulate user flows, log watchers that catch runtime errors, observable signals that tell the agent whether what it built actually works.
The OpenAI Harness Engineering article described using LogQL to surface relevant logs during validation runs so the agent could check whether the data was correct, not just whether the tests passed. That is the kind of layered validation that turns an agent with good intentions into an agent that ships reliable code.
The mental model I use: your agent is a junior engineer who works very fast and does not ask questions. The validation loop is the PR review. Without it, you are merging everything without reading it.
Pillar 3: Agentic Tooling#
Peter Steinberger described this pillar in terms of friction. What are the things that block the agent? What causes the agentic loop to stall, to require a human to step in, to hand back control because the agent cannot proceed?
Every one of those friction points is an engineering opportunity.
OpenClaude is a good example of this thinking at scale. It started as a collection of CLI tools built to do things Claude could not do on its own. Browser automation. API calls. File system operations that needed specific handling. Each tool removed a category of friction. Over time, the collection of tools became more valuable than any individual tool, because agents could chain them together in ways nobody had explicitly designed.
The principle from the Steinberger framing that I have tried to internalize: when you encounter something in your workflow that requires a human to do manually, treat that as a defect. Not in the agent. In the system around the agent.
You are going to a website to click a button that could be an API call. You are copying a value from one system to another because there is no integration. You are approving something that should be automated. Each of these is a signal that a tool is missing. Build it.
The question I try to ask myself now, when I catch myself doing something manually: how would I build a CLI tool that lets the agent do this instead? Sometimes the answer is ten minutes of work. Sometimes it reveals a real integration problem that was always there. Either way, the answer is better than accepting the friction.
Pillar 4: Agentic Code Bases#
This is the pillar that requires you to look at existing code with uncomfortable honesty.
Most codebases are not ready for agents. This is not a criticism. Codebases accumulate the same way decisions do. A migration that never finished. Two different patterns for the same thing, both present, both technically working. Dead code that nobody has time to remove. Documentation that was accurate six months ago.
For a human engineer, this is manageable. You have context. You know which pattern to follow. You ask someone when you are unsure.
An agent has none of that. It reads what is there and tries to infer from probability which direction to go. When your codebase has competing patterns, the agent picks one. Sometimes the right one. Sometimes not. And unlike a human who notices they picked wrong and course-corrects, the agent builds on the wrong choice until something breaks.
The engineers at OpenAI who wrote about Harness Engineering described going further than just cleaning up dead code. They optimized their file structure for consistency so the agent could generate new files without needing to infer the right location. They added agent-specific logging so validation runs would surface relevant signals. They encoded what they called golden principles directly in the repository, opinionated rules that the agent could follow reliably.
The reframe that shifted how I think about this: you are not writing code for the next engineer anymore. You are writing code for the next agent. The agent that will read your patterns and extend them. The agent that will follow your documentation or not, depending on whether it exists and whether it is accurate.
I have a specific habit now that came from this. Before running an agent on any nontrivial task, I ask: if an agent reads this code cold, will it understand which pattern to follow? If the answer is no, I fix that first.
For more on the architecture side of agent-ready codebases, the section on agent-friendly code in the AI-native engineer framework covers this from a different angle. The short version: tests as contracts, accurate documentation, and pattern uniformity. These are not agent problems. They are codebase hygiene problems that agents reveal with unusual efficiency.
Pillar 5: Compound Engineering#
Dan Schipper, co-founder of Every, named this one. The concept is straightforward but the implications are large.
When all four previous pillars are working, something starts to happen. Each improvement compounds. A new CLI tool goes into the shared codebase and becomes available to every agent on the team. A documentation file that one engineer writes benefits every subsequent run. A validation mechanism built for one task turns out to work for related tasks. The second brain of domain knowledge grows, and every agent that runs benefits from what was added before.
This is the opposite of the pattern I see in most teams right now, where every engineer has their own workflows, their own prompts, their own local customizations. Those things do not compound. They diverge.
The compound engineering model looks more like what the OpenAI team described: everyone bought into a shared framework, tools landing in a working library, context accumulating in the codebase rather than in individual engineers' heads. The result is that agents get progressively more capable not just because the models improve but because the environment around them gets better.
The compounding does not happen automatically. It requires someone to be thinking about shared infrastructure, not just their own workflow. That is a new engineering role that does not have a great name yet. But the teams building it now will be significantly ahead of the ones who figure it out later.
This is also why the pillar pattern matters: you cannot skip to compound engineering. You need context engineering first, so there is something useful to share. You need validation, so shared tools produce reliable output. You need agentic tooling, so the shared library has things worth sharing. You need clean codebases, so agents running across the team are not poisoned by inconsistency.
The compound value is the payoff. The other four pillars are how you earn it.
What This Means in Practice#
I am still figuring this out. Some days I spend four hours building a validation tool for the agent and it does not work and I wonder if I should have just written the code myself.
The honest answer is: probably not. The instinct to take back control is real and sometimes correct. But if you let it run the show, you never build the systems that make agents reliably useful.
A few things I have changed in my actual workflow based on these pillars:
I treat my CLAUDE.md as a living document. When I notice the agent going in a direction I did not want, the first question I ask is: what is missing from the context? Not "what is wrong with the prompt?"
I build validation before I build features. This one is uncomfortable because it feels like extra work. It is not. It is the work that makes everything else reliable.
I keep a running list of things I do manually when working with agents. Each item on that list is a future CLI tool or skill. The list never gets to zero, but it gets shorter.
I clean up competing patterns before running agents on a codebase. Even ten minutes of pattern cleanup before a session is worth it.
For the orchestration mechanics underneath all of this, Building Production-Ready Multi-Agent Systems goes into more depth on state management and error handling. And if you are wondering how many agents to run at once, Before You Run 10 Claude Agents covers the practical progression. For infrastructure-level enforcement of the isolation principle, Google's Scion applies bounded agency through containers and worktrees rather than relying on prompt-level constraints.
The era of engineering by hand is not over, but the ceiling of what one engineer can build is rising fast. The difference between engineers who understand the five pillars and engineers who are still prompting and hoping is going to keep widening, month over month. The gap is already visible to anyone paying attention.
FAQ#
What is agentic engineering?#
Agentic engineering is the practice of intentionally designing the systems, context, tools, and code environment that AI coding agents operate within. It is distinct from vibe coding, which describes a more improvised approach where you prompt an agent and react to what it produces. Agentic engineering treats the agent as a component in a system that you have designed and can improve over time.
What is the difference between agentic engineering and vibe coding?#
Vibe coding is reactive. You prompt, you see what comes out, you adjust. Agentic engineering is proactive. You design context, validation loops, tooling, and codebase structure before the agent runs, so it has the best chance of producing reliable output. The difference becomes especially significant on complex, multi-session tasks where accumulated context and validation infrastructure make a large difference in output quality.
What is context engineering for AI agents?#
Context engineering is the practice of thinking carefully about what information you provide to an AI model. Rather than trying to include everything, the goal is to provide exactly the right information, fresh and condensed, so the model can produce useful output. CLAUDE.md files, skills, and MCPs are all context engineering tools. The key insight is that more context is not always better, and irrelevant or conflicting context actively degrades output.
Why does codebase quality matter more for agents than for human engineers?#
Human engineers have implicit context. They know which pattern to follow when two exist. They ask questions when they are unsure. Agents do not. An agent infers what to do from what is in the codebase. If the codebase has dead code, competing patterns, or inaccurate documentation, the agent treats those as valid signals and produces output that reflects the inconsistency. Clean codebases produce better agent output, and the gap is larger than most people expect.
What is compound engineering?#
Compound engineering is what happens when all the other pillars work together across a team over time. Each improvement to the shared environment becomes available to every agent that runs in it. Tools, documentation, validation mechanisms, and encoded domain knowledge accumulate. The result is that the team's collective AI capability grows faster than any individual's workflow improvements would suggest.
How do I start with agentic engineering if my codebase is messy?#
Start with context engineering. Before trying to fix the codebase, make sure you have a good CLAUDE.md or equivalent briefing document that tells the agent what patterns to follow and what to avoid. Then add simple validation: even running the test suite after each agent change is a meaningful start. The codebase cleanup is a longer project, but you can make agents meaningfully more useful without it by being precise about context.
Is agentic engineering only relevant for large engineering teams?#
No. A solo developer can apply all five pillars. The compound effect is most visible in teams because shared infrastructure benefits more people. But context engineering, agentic validation, and building CLI tools for your own workflow pay off at any scale. The habits you build working alone become the foundation for compound engineering when you eventually add teammates.