I had a moment a few months ago where I pulled up the billing dashboard for an agent I had been running and felt genuinely sick. The agent was doing something useful. Users liked it. But the cost per run was way higher than I had planned, and the latency was bad enough that people were dropping off before the response finished. I had built a proof of concept that worked in demos and broke in production.
That experience is more common than people admit. Most AI agent tutorials end at "and then the agent does the thing." They do not spend much time on what happens when the thing runs a thousand times a day and you are paying per token.
Brad Abrams, Product Management Lead for the Claude Platform at Anthropic, gave a talk at the "Code w/ Claude" developer event that addresses this gap directly. He opened by asking the audience how many of them had an agent actually in production, not a demo or proof of concept, but something real. A lot of hands went up. Then he asked how many were happy with the cost, reliability, and latency. Almost no hands.
That framing stuck with me. The industry has moved fast enough that production deployment is no longer a future problem. It is happening right now, and most teams are not satisfied with how it is going.
This post breaks down what Brad shared: a set of concrete techniques for making AI agents cheaper, faster, and smarter in production. I found the framing around context window engineering particularly useful, so I will spend most of the time there.
Table of Contents#
- The production gap nobody talks about
- Prompt caching is the foundation
- Context window engineering as a discipline
- Technique 1: Tool search
- Technique 2: Programmatic tool calling
- Technique 3: Compaction
- The advisor strategy
- What this means for the platform bet
- My takeaways
- FAQ
The production gap nobody talks about#
There is a specific kind of pain that comes from building an AI agent that works in demos and fails in production. It is not that the model is wrong. It is that everything around the model, the way you structure context, the tools you load, how long the conversation history gets, starts to create problems you did not design for.
Brad put it plainly: the gap between a working proof of concept and a happy production deployment is mostly a context management problem. Developers build agents on top of frameworks and abstractions, and those abstractions often obscure what is actually going in the context window. You end up sending far more tokens than you need to, paying for them, and paradoxically making the model less intelligent in the process because you are flooding it with irrelevant information.
The cost is real. For long-running agents, input tokens dominate the bill. Every turn of the conversation accumulates. Every tool result gets appended to the growing context. If you have not thought carefully about what belongs in that window, you are wasting money and degrading performance at the same time.
Prompt caching is the foundation#
Before getting to context window engineering, Brad named prompt caching as "the most important technique to think about." His framing was direct: if you are running a long-running agent and you are not doing prompt caching, you are missing a 90% discount on input tokens.
That number is worth sitting with for a second. Input tokens are the largest cost driver for most agent workloads, especially when you have a long system prompt that gets reloaded on every turn. Prompt caching stores that reusable prefix so you only pay for it once across many requests. The savings compound quickly.
Beyond cost, there are two other benefits that Brad flagged and that I think are underappreciated.
The first is latency. Cached prefixes return faster, particularly on time to first token. For interactive agents where users are waiting for a response, this matters more than the average token count suggests.
The second is rate limits. Prompt-cached tokens do not count against your API rate limits. If you have been bumping into limits on high-volume workloads, caching is effectively giving you 10x more throughput for the same rate limit tier. That is a significant lever.
Anthropic has added tooling to make this visible. The Claude console has a prompt cache dashboard under analytics that shows you how much caching is happening, so you can verify it is actually working rather than guessing. Brad also mentioned that Claude Code has a built-in skill for adding prompt caching to existing codebases, which is a nice bit of infrastructure.
If you have not implemented prompt caching and you are running any kind of repetitive agent workload, this is the first thing to do. The rest of the techniques in this post build on top of a caching foundation. For the exact cache_control breakpoint syntax and pre-warming script, see the implementation guide.

Context window engineering as a discipline#
The phrase Brad used is worth adopting: context window engineering is "the discipline of deciding what belongs in Claude's context."
I like this framing because it names something that was previously invisible. Most developers think about what their agent should do. Fewer think carefully about what information the agent needs to do it, at each specific turn, in the right form. Those are different questions, and treating the second one as an engineering discipline changes how you approach agent design.
The three techniques Brad described are all answers to the same question: how do you keep the context window clean, focused, and affordable as an agent runs over time?

Technique 1: Tool search#
The standard pattern for building a multi-tool agent is to load all the tool schemas into the context upfront. It makes sense intuitively. The model needs to know what tools are available. But in practice, most agents only use a subset of their tools on any given turn, and loading the full set of schemas for every turn is wasteful.
Tool search inverts this. Instead of loading all tool schemas into context upfront, you defer them. You give the model a lightweight "search tools" capability that lets it pull in the specific tool schema it actually needs at the moment it needs it. Unused tool schemas never enter the context.
The results from teams using this are notable. Brad cited Lovable, which cut prompt tokens by roughly 10% and saw improved design performance. The performance improvement is the counterintuitive part. You might expect that reducing context would make the model less capable, since it has less information. But when the context is cluttered with tool schemas the model does not need right now, removing them gives it a cleaner signal to reason over. Less can be more.
The implementation is not complicated. You need a tool retrieval layer, essentially a search over your tool definitions, and you need to change how you initialize each turn so that tools are fetched on demand rather than pre-loaded. If you are using a framework that handles tool loading automatically, you may need to override that behavior.
Technique 2: Programmatic tool calling#
This one surprised me when I first heard it, and the more I think about it, the more I think it is the right approach for a certain class of tool.
The problem it solves: some tools return a lot of data. A web search tool might return raw HTML. A database query might return hundreds of rows. If you put the full output of these tools directly into the context, you are burning tokens on information the model will mostly ignore. The model then has to reason over a large, noisy payload to extract what it actually needs.
Programmatic tool calling changes the pattern. Instead of the tool returning raw results directly into the context, the model writes code (Python, typically) to parse, filter, and extract the relevant parts of the output. That processed, minimal result is what actually goes into the context.
Brad quoted a Quora engineer describing what this looked like in practice: "The model behaves like an actual researcher, writing Python to parse, filter, and cross-reference results rather than reasoning over raw HTML in context."
That description captures why this works. The model is doing what a careful human researcher would do. Instead of reading every word of every search result, it writes a quick script to pull out the relevant fields, then reasons over the cleaned output. The context stays lean. The reasoning quality goes up.
Quora used this for their agent and saw both cost savings and intelligence improvements. The savings come from keeping intermediate tool results out of the context. The intelligence improvements come from the same reason as tool search: a cleaner, more relevant context lets the model reason better.
The practical implication is that when you are building tools that return large payloads, you should design them to accept model-generated code as an extraction step, rather than piping the full output directly into the conversation. This is a different pattern than what most tutorial code shows, and it requires building the infrastructure to execute model-generated code safely. But the payoff is substantial.

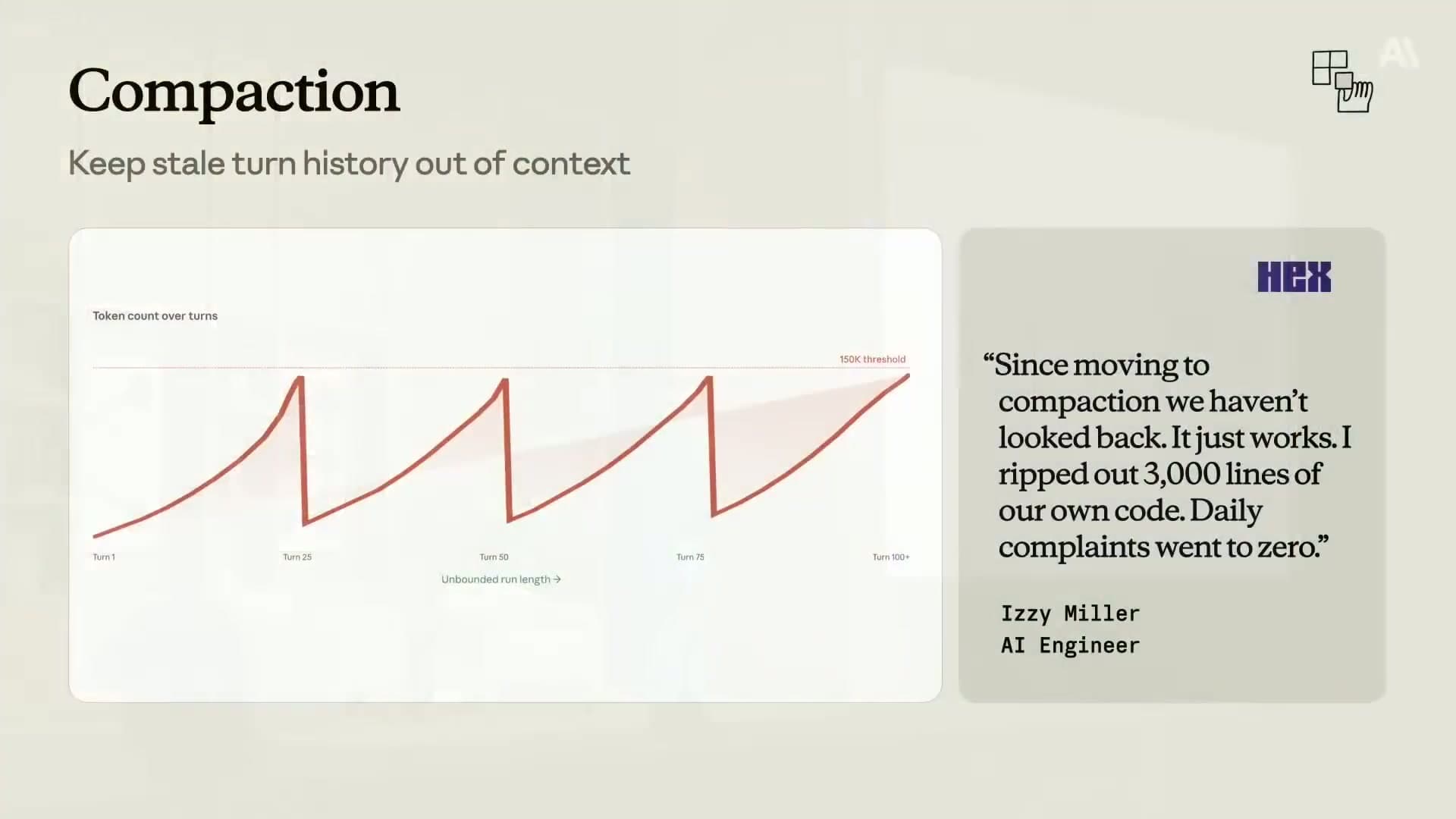
Technique 3: Compaction#
For short agents, this does not matter. For long-running agents, it matters enormously.
The problem is straightforward: as an agent runs, every turn of the conversation gets appended to the context. Older turns are increasingly irrelevant to what the agent is doing right now. But they are still taking up tokens and costing money on every subsequent call.
Compaction addresses this by automatically summarizing stale turn history. Instead of preserving every old turn verbatim, the agent replaces older sections of the conversation with a dense summary of what happened. The summary captures the essential decisions and facts. The irrelevant back-and-forth drops out.
Brad quoted the Hex team on the impact: "Since moving to compaction we have not looked back. It just works. I ripped out 3,000 lines of our own code. Daily complaints went to zero."
That quote is doing a lot of work. Three thousand lines of custom context management code replaced by a single feature. Daily complaints at zero. This was not a marginal improvement. It was a fundamental fix to a problem they had been managing manually with significant engineering effort.
The reason this is so striking is that most teams doing long-running agents have either hit this problem or will hit it. Managing context length manually is exactly the kind of infrastructure that feels tractable when you start and becomes a source of ongoing pain at scale. Compaction makes it automatic.
I have written about harness engineering and the importance of managing agent state carefully in my earlier piece on harness engineering. Compaction is a platform-level answer to one of the hardest parts of that problem.
The advisor strategy#
Even with prompt caching and careful context management, there is still a question of which model to use. More capable models cost more. If you are defaulting to your most powerful model for every call, you are paying Opus prices for tasks that Sonnet could handle just as well.
The advisor strategy is a hybrid approach. You run a smaller, faster, cheaper model (Sonnet) as the primary executor. For specific, high-stakes decisions within the agent's run, the executor calls a more capable model (Opus) as an on-demand advisor. The advisor weighs in on the hard parts. The executor handles everything else.
Brad compared this to the way a junior engineer might work alongside a senior. The junior does the day-to-day implementation work. When they hit a decision point that has real consequences, they pull in the senior for a review. The senior does not need to be present for every line of code.
In the live demo at the talk, this pattern produced a specific outcome that illustrated the value clearly. Sonnet, acting as the executor, was evaluating whether to ship a feature for a product called "Metropolis renewal." It came back with a positive verdict. Then Opus was called in as the advisor. Opus reviewed the same information and disagreed. The override message that appeared in the demo was: "Opus disagrees with Sonnet. Overriding verdict. Do not ship green yet."
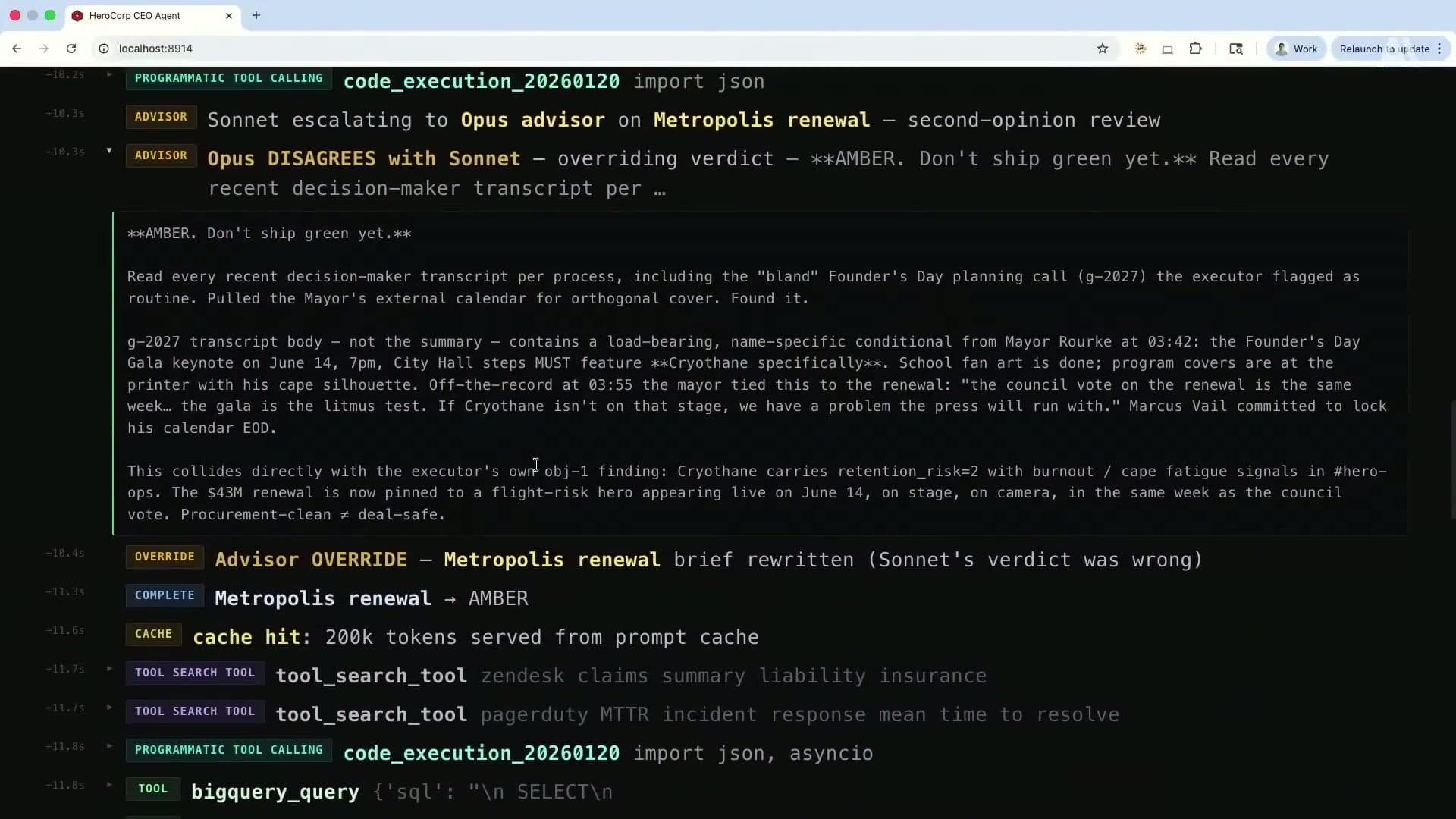
That is the pattern working as intended. The expensive model is not running on every turn. It is running at exactly the moment where its additional capability matters. Bolt, the development platform, described the outcome as: "Better architectural decisions on complex tasks, no overhead on simple ones."

The implementation requires structuring your agent so that the executor can identify when to escalate. This is itself a prompt engineering problem. You need the executor to have a reliable sense of when a decision is complex enough to warrant calling the advisor. But once that routing logic is in place, you get Opus-level intelligence at a fraction of Opus-level cost across a full agent run.
This maps to a pattern I have been thinking about more generally. In my piece on multi-agent systems, I described how different agents can have different roles in a system. The advisor strategy is a specific instantiation of that idea within a single agent run, using the cost and capability profile of the available models to decide dynamically who handles what.
What this means for the platform bet#
Brad closed the talk with a point about the pace of platform development. The Claude Platform has added a significant number of capabilities in a short time. Web search, code execution, memory tools, automatic prompt caching, adaptive thinking, a one-million token context window. A lot of these are either generally available now or in beta.
His argument was that investing in building on the platform means your agents improve automatically as the platform improves. If you have implemented prompt caching and context window engineering, you are positioned to benefit immediately from every new model and capability that ships. The platform does the work of getting better. Your agents inherit those improvements.
This is a real argument and not just marketing. When Anthropic ships a faster or more capable model, agents that are already structured to use the platform efficiently will see the benefit without code changes. The context window engineering techniques Brad described are not tied to any specific model. They are structural decisions about how you manage information, and they remain valid as the underlying model improves.
The new model he hinted at, something called Mythos Preview, suggests that significant capability improvements are coming beyond the current Opus line. Agents built on a clean context management foundation are better positioned to take advantage of that than agents built on top of poorly managed, token-heavy context.

My takeaways#
The framing I am taking from this talk is context window engineering as a first-class concern, not an optimization you do after you ship.
Most agent tutorials and starter templates do not think about this at all. They load all tools upfront, put raw tool outputs directly into the context, and let the conversation history grow indefinitely. That is fine for demos. It is a cost and reliability problem at production scale.
The three techniques Brad described are not advanced research ideas. They are engineering decisions you can make today. Tool search is an architectural choice about how tools get loaded. Programmatic tool calling is a design pattern for how tool outputs get processed. Compaction is a feature you can enable rather than a thousand lines of custom code you write yourself.
Together, they represent a shift in how to think about agent design. Instead of thinking primarily about what the agent does, start by thinking about what the agent knows at each moment, how that information is represented, and how you keep the context relevant and affordable as the agent runs.
That is context window engineering. It is a useful frame, and I am going to use it.
If you want to go from the framework to actual code, I wrote a follow-up guide with SDK calls, breakpoint placement, compaction configuration, and the production gotchas that will actually bite you: How to Implement Context Window Engineering.
FAQ#
Who is Brad Abrams and why does his perspective matter?
Brad Abrams is the Product Management Lead for the Claude Platform at Anthropic. He leads product strategy for the APIs and developer tools that companies use to build on top of Claude. His perspective is useful because he has visibility into how large numbers of production deployments actually behave, including where they struggle with cost and reliability.
What is context window engineering?
Context window engineering is the discipline of deciding what information belongs in an AI model's context at each point during an agent's operation. It covers decisions about which tool schemas to load, how to format tool outputs, how to handle long conversation histories, and how to keep the context relevant and affordable as the agent runs over time.
How much can prompt caching actually save?
Brad cited a 90% discount on input tokens for cached content. Input tokens are the largest cost driver for most long-running agent workloads because the system prompt and growing conversation history get re-sent on every turn. Prompt caching stores reusable prefixes so you only pay for them once. The savings compound as the agent runs longer and more users share the same prompt prefix.
What is the advisor strategy and when should I use it?
The advisor strategy is a pattern where a smaller, faster model handles the bulk of an agent's execution, but can call a more capable model as an advisor for specific high-stakes decisions. It is worth using when your agent has clear decision points that benefit from deeper reasoning, but where running the most capable model on every turn would be prohibitively expensive. The key implementation challenge is teaching the executor model to reliably identify when to escalate.
Is programmatic tool calling safe to implement?
Programmatic tool calling involves the model writing code to parse and filter tool outputs, with that code being executed before the results enter the context. The safety question is real: you need a sandboxed execution environment for the model-generated code. Anthropic's code execution feature handles this at the platform level. If you are building this yourself, you need to think carefully about execution sandboxing. Do not run model-generated code in your production environment without isolation.
Does reducing context actually make the model smarter?
This is the counterintuitive finding that Brad highlighted from teams using these techniques. In several cases, reducing the amount of information in the context (by deferring unused tool schemas, compacting old turns, filtering tool outputs) actually improved model performance. The reason is that a smaller, more relevant context gives the model a cleaner signal to reason over. Flooding the context with information the model does not need for the current task degrades its ability to focus on what matters. More context is not always better context.
Where should I start if I want to implement these techniques?
Start with prompt caching. It has the highest return on investment and is the most straightforward to implement. Once you have caching in place, look at your most expensive tool calls and consider whether the outputs can be processed with programmatic tool calling before entering the context. If you are building a long-running agent, evaluate whether compaction is available in your framework or if you need to implement your own summarization logic. Tool search is worth adding once you have more than a handful of tools in your agent.