Workflow Topology
Pattern 04 of 9
Evaluator-Optimizer
Generate, evaluate, and revise in a loop until output meets a quality threshold.
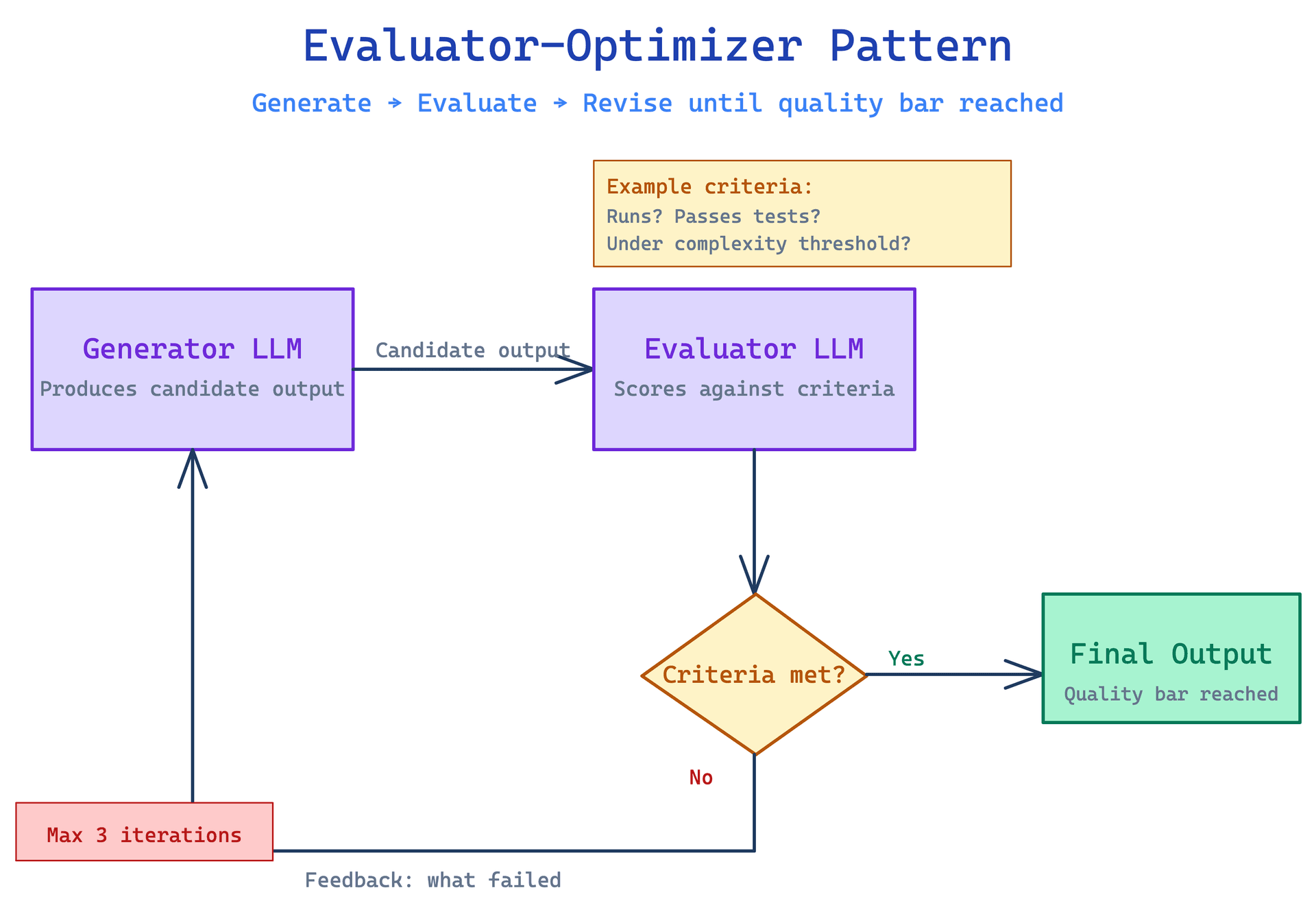
The evaluator-optimizer pattern runs generation and evaluation as a closed loop. A generator model produces an initial output. An evaluator model, which may or may not be the same model, scores or critiques that output against defined criteria. If the output does not meet the threshold, the critique is fed back to the generator as context for a revised attempt. The loop runs until the evaluator approves the output or a maximum iteration count is reached.
Why it matters
A single pass through an LLM is often not good enough for high-stakes output. The model makes mistakes, misses requirements, or produces something technically correct but practically wrong. The evaluator-optimizer pattern gives you a systematic way to iterate without human involvement at every step. It trades compute for quality, which is often a worthwhile exchange when the output will be read by a customer, published externally, or used as input to a consequential decision.
Deep Dive
The generator and the evaluator can be different models, the same model with a different system prompt, or the same model in a self-critique mode. Using different models is often better in practice. A model critiquing its own output tends to be more charitable than a separate model critiquing it. The separate evaluator sees the output fresh, without the generative context that produced it, and is more likely to notice what is missing or wrong. When cost is a concern, you can use a smaller model as the evaluator, provided it can reliably detect the failure modes you care about.
Criteria specification is the most important design decision in this pattern. If your evaluator criteria are vague, the evaluator will produce vague critiques and the loop will not converge. Criteria should be concrete and binary where possible: does the output contain a specific required field, is the word count within range, does the claim have a citation. Rubric-style evaluation, where the evaluator scores multiple dimensions separately, works better than a single overall quality score because it gives the generator specific feedback about what to fix in the next iteration.
The Reflexion paper from 2023 extends this pattern by storing evaluative feedback in a persistent memory across episodes, not just within a single run. Instead of discarding critique at the end of each task, the agent accumulates a set of learned lessons it can consult on future tasks. This is the difference between within-task optimization, which is what the basic loop does, and across-task learning, which is what Reflexion adds. For production systems that handle many similar tasks, the Reflexion approach can meaningfully reduce the number of iterations needed on later tasks by encoding what the evaluator learned from earlier ones.