Workflow Topology
Pattern 07 of 9
Reflexion
Verbal self-reflection on failure, stored as context that improves future attempts.
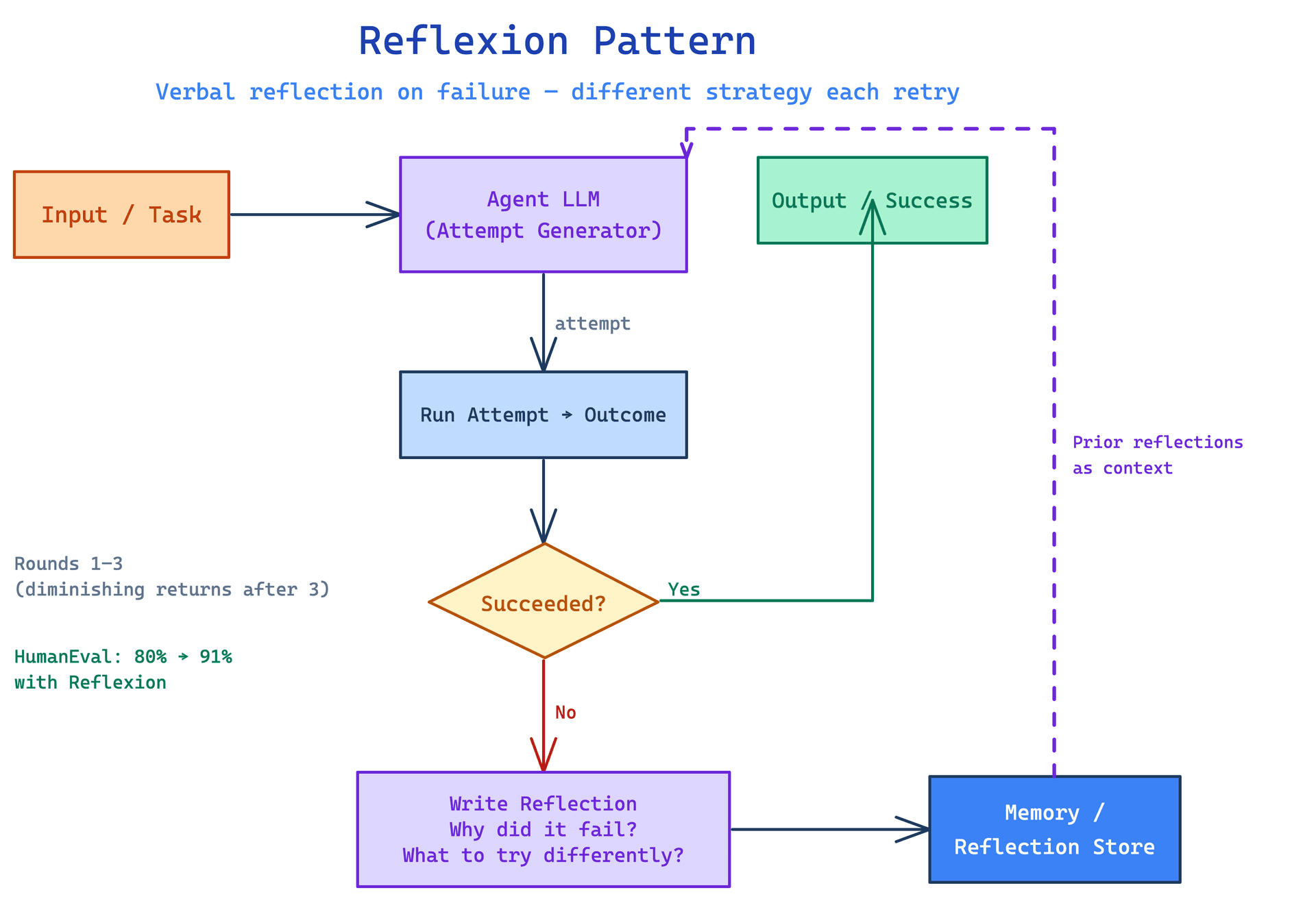
Reflexion extends the standard agent loop with explicit verbal self-reflection. When an agent fails a task or receives negative feedback, instead of just retrying, it produces a written reflection: a natural-language post-mortem that identifies what went wrong and what it should do differently. That reflection is stored in the agent's memory and retrieved as context on subsequent attempts, either at the same task or at similar tasks in the future. The agent learns from failure through language, not gradient updates.
Why it matters
Standard agent loops fail and retry but do not learn. The same mistakes recur because nothing about the failure is preserved between attempts. Reflexion gives the agent a mechanism to encode failure-derived lessons in a format it can actually use: natural language, in context. For tasks where the failure mode is a specific misjudgment or oversight rather than a random error, verbal reflection can substantially reduce the number of attempts needed.
Deep Dive
The Reflexion paper from Shinn et al., published in 2023, introduced this pattern in the context of task agents operating on environments like AlfWorld and HotpotQA. The core insight is that language models are already good at post-hoc analysis when given a task description and the trace of what happened. If you show the model what it tried and what failed, it can usually articulate a plausible account of why. That articulation, rather than the raw failure trace, is what gets stored in memory. The articulation is compressed and semantically meaningful in a way that a raw log is not.
Memory storage and retrieval is the engineering challenge this pattern introduces. For within-episode reflection, the reflection just gets appended to the context window. For cross-episode reflection, you need a retrieval mechanism: typically a vector store indexed by task description or failure type, with similarity search to surface relevant past reflections at the start of a new attempt. The quality of the retrieval determines how often the right lesson is present when the agent needs it. This is the same problem as general retrieval-augmented generation, but the documents are reflections rather than external knowledge.
There is a failure mode worth naming: confident wrong reflections. If the agent misdiagnoses why it failed, the stored reflection encodes a bad lesson. On the next attempt, the agent applies the wrong fix, fails again, and may produce another wrong reflection doubling down on the first error. This positive feedback loop is hard to break automatically. Mitigations include capping the number of times a reflection is applied before it gets reviewed, adding a separate verifier step that evaluates reflection quality before storage, or flagging repeated failures at the same task for human review. None of these are automatic but they contain the damage.