I rewrote a section of my CLAUDE.md last month and had no idea whether it made things better or worse.
I thought I was being precise. I restructured the instructions, tightened the wording, removed a "verify" step that felt redundant. Then I ran Claude Code on a few tasks and watched what happened. The output seemed about the same. Maybe slightly better. Possibly slightly worse. I genuinely could not tell.
That uncertainty is not a workflow problem. It is a measurement problem. And until recently, there was no real solution to it.
Minko Gechev, who works on developer experience at Google, published something last week that changed how I think about this. It is called Skill Eval. The core idea is simple and slightly embarrassing in how obvious it is once you hear it: skills are code for agents, so you should test them the way you test code.
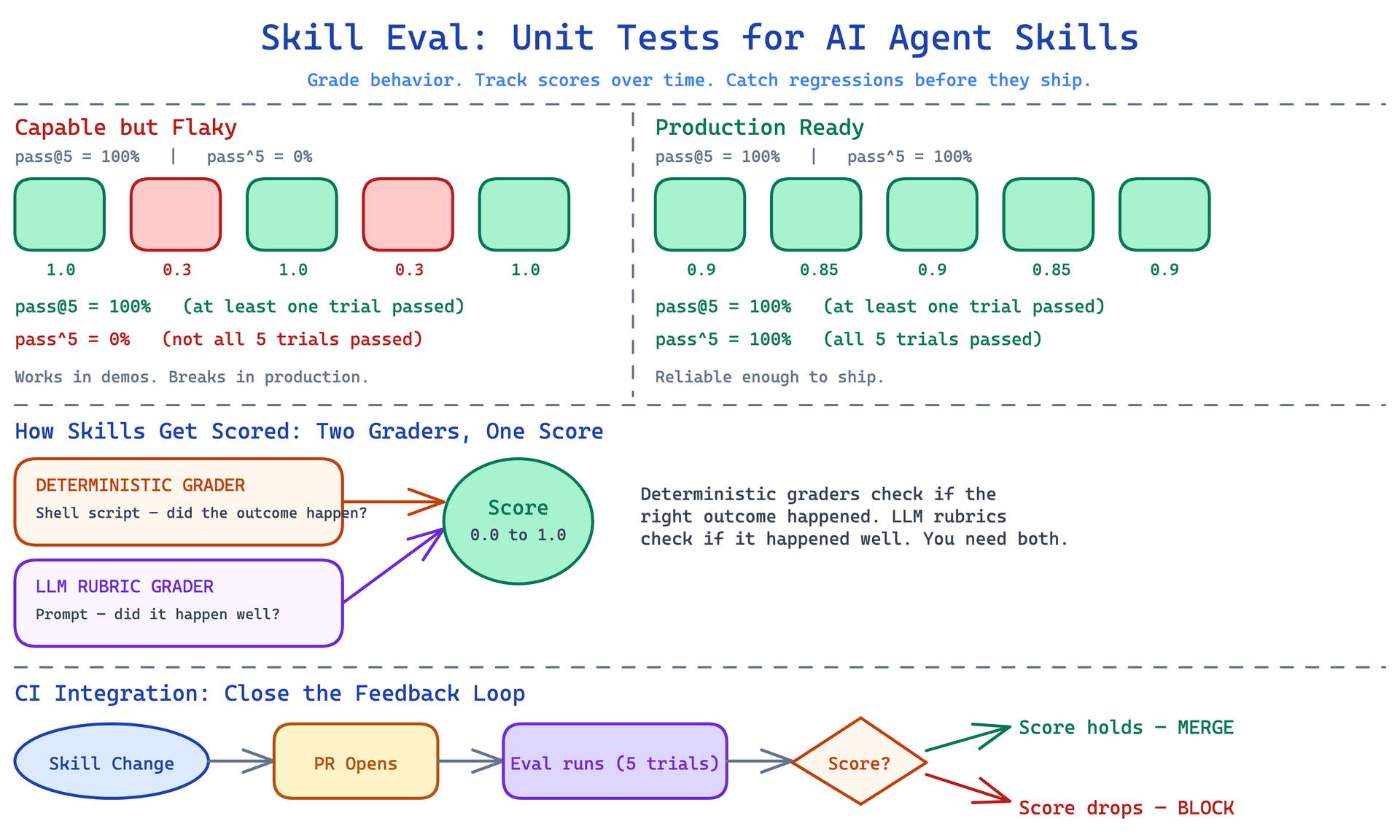
Table of Contents#
- The problem with testing AI agent skills
- What skill evaluation actually looks like
- Two kinds of correct: deterministic and LLM graders
- The pass@k vs pass^k distinction
- CI integration and the DevOps loop
- What this changes about how you maintain skills
- FAQ
The Problem With Testing AI Agent Skills#
The way most teams manage AI agent skills right now is close to the way we managed code before version control existed. You write something down. You try it a few times. It seems to work. You move on. When something breaks later, you have no way to know whether it was the skill change you made last Tuesday or something else entirely.
The precise quote from Gechev's post stuck with me: "There's no way to know if they actually work. You write a text file, hand it to an agent, and hope for the best."
That is an accurate description of most skill management I have seen, including my own.
The insidious part is what he calls silent degradation. A small change, rewording a step, reordering instructions, removing a command that you thought was redundant, can break the agent's behavior without any obvious signal. The agent still runs. It still produces output. The output just stops following the skill reliably. You only find out when someone notices that the agent is not doing what it is supposed to do, which is often a long time after the change.
This is the same failure mode that drove the adoption of unit tests for code. Code changes break things silently all the time. The solution was not to be more careful about making changes. It was to build automated verification that runs every time you make a change, tells you immediately whether something broke, and gives you a number you can track over time.
Skills need the same thing. They are procedural instructions that govern agent behavior. They have inputs, expected outputs, and edge cases. They should have tests.
What Skill Evaluation Actually Looks Like#
Skill Eval is a TypeScript framework that runs your agent against a defined task inside a Docker environment and scores the result on a scale from 0.0 to 1.0.
Here is what an actual run looks like from Gechev's post:
superlint_demo | agent=gemini provider=docker trials=5
Trial 1/5 ▸ reward=1.00 (55.0s, 2 cmds, ~716 tokens)
Trial 2/5 ▸ reward=0.91 (33.1s, 2 cmds, ~798 tokens)
Trial 3/5 ▸ reward=0.70 (46.8s, 2 cmds, ~798 tokens)
Trial 4/5 ▸ reward=0.70 (40.5s, 2 cmds, ~648 tokens)
Trial 5/5 ▸ reward=0.70 (48.4s, 2 cmds, ~650 tokens)
Pass Rate: 80.2% | pass@5: 100.0% | pass^5: 100.0%
Avg Duration: 44.8s | Avg Commands: 2.0 | Total Tokens: ~3610
A few things stand out immediately. The rewards vary across trials for the same task: 1.00, 0.91, 0.70, 0.70, 0.70. This is not a bug. This is the nondeterminism of LLM-based agents showing up in your evaluation data, which is exactly where you want to see it rather than discovering it in production.
Each task lives in a directory that contains everything needed to evaluate it:
tasks/my_task/
├── task.toml # Timeouts, graders, resource limits
├── instruction.md # What the agent should do
├── environment/Dockerfile
├── tests/test.sh # Deterministic grader
├── prompts/quality.md # LLM rubric grader
├── solution/solve.sh # Reference solution
└── skills/my_skill/
└── SKILL.md
The Docker environment matters more than it might appear. It means the evaluation runs in an isolated, reproducible environment every time. The same task, the same starting conditions, different trials to capture the variance. This is how you separate genuine skill degradation from noise.
Two Kinds of Correct: Deterministic and LLM Graders#
The grading system is where the design gets interesting. Skill Eval supports two types of graders, and the distinction captures something real about what correctness means for agent tasks.
Deterministic graders are shell scripts that check whether the outcome meets a specific, measurable criterion. Did the agent create the right file? Does the output match the expected format? Did the linter pass? These are binary or near-binary evaluations. Either the thing happened or it did not. The test script produces a score, and the score does not vary based on interpretation.
LLM rubric graders are prompts that evaluate qualitative aspects of the agent's output. Was the explanation clear? Did the agent handle the edge case appropriately? Did it follow the style guidelines in a way that a human reviewer would approve? These evaluations require judgment, not just pattern matching. The grader is an LLM reading the output against a rubric and producing a score.
Using both together is the right approach. Deterministic graders tell you whether the agent did the right thing. LLM rubric graders tell you whether the agent did it well. A skill could pass the deterministic test while still being poor in ways the shell script cannot capture. A skill could produce output that looks high quality to the LLM rubric while still failing on a specific measurable criterion.
This mirrors how human code review works. Automated tests check whether the code is correct. Code review checks whether the code is good. You need both.
The pass@k vs pass^k Distinction#
This is the part of the post I found most immediately useful, and it is not obvious until someone explains it.
Both metrics involve running the agent multiple times on the same task. The difference is what question they answer.
pass@k asks: can the agent do this at all? If you run five trials and the agent succeeds on at least one of them, pass@5 is 100%. This tells you whether the capability exists. If pass@5 is 0%, the agent fundamentally cannot do this task, and your skill needs significant work. If pass@5 is 100%, the capability is there.
pass^k (read as "pass-all-k") asks: can the agent do this reliably? It measures whether the agent succeeds on every one of the k trials. pass^5 = 100% means the agent succeeded all five times. This is a much stricter standard.
The combination tells you something specific and actionable.
If pass@5 is 100% but pass^5 is 30%, the agent can do the task but is flaky. It succeeds sometimes and fails others. In a demo, it looks fine. In production, where the agent runs the task many times across many users, the 70% failure rate shows up as a reliability problem.
If pass@5 is 60%, the agent cannot consistently do the task even in the best case. The skill needs fundamental revision, not just reliability tuning.
If pass^5 is 100%, you have a reliable skill. It may be worth relaxing this to pass^5 at some lower threshold like 80% depending on the tolerance for failure in your specific use case. But the metric gives you a number to reason about rather than a vague sense of "seems to work."
The practical workflow this suggests: use pass@k during skill development to verify that the capability is achievable at all, then switch to pass^k before shipping to verify that the capability is reliable enough for production.
This maps directly onto the define-evaluate-monitor loop from the agentic cost framework. Define what the skill should do. Evaluate whether it does it (pass@k). Monitor whether it does it reliably (pass^k). The metrics give each step a concrete number to track.
CI Integration and the DevOps Loop#
Gechev recommends integrating Skill Eval into GitHub Actions, running evaluations on any pull request that touches skill files or task definitions:
name: Skill Eval
on:
pull_request:
paths: ['skills/**', 'tasks/**']
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
- run: npm install
- run: npm run eval my_task -- --trials=5 --provider=docker
This is where the analogy to unit tests becomes fully concrete. You do not merge code without running the test suite. You should not merge skill changes without running the eval suite.
The CI integration closes the loop that most teams currently leave open. Right now, the typical skill management workflow is: write the skill, try it manually a few times, feel reasonably confident, commit. There is no automated check. There is no score that tells you whether the change made things better or worse. There is no protection against the slow degradation where a series of small changes that each seem fine produce a skill that is significantly worse than what you started with.
With CI integration, every change to a skill file triggers a scored evaluation. If the score drops below a threshold, the pull request does not merge. The feedback loop tightens from "I found out three weeks later when someone complained" to "I found out before I pushed."
This is precisely what the monitoring pillar in The Five Pillars of Agentic Engineering points toward. The DevOps analogy for agentic systems is not just a metaphor. It is a literal workflow that now has tooling to support it.
What This Changes About How You Maintain Skills#
If you take the Skill Eval approach seriously, it changes a few things about how you think about skills.
Skills become versioned, tested artifacts. Right now, most teams treat skill files like configuration, not like code. They get edited informally, committed without review, and updated based on feel. With evals, you have a score attached to each version. You can see when a change improved performance and when it made things worse. You can roll back with confidence because you have a metric that tells you whether the rollback actually helped.
Skill authorship becomes a distinct skill. Writing clear, testable skill files is harder than writing vague ones. A skill that is testable has to specify what the agent should actually do in terms concrete enough to evaluate. This specificity is uncomfortable when you are not sure exactly what you want, but it forces the clarity that context engineering requires. The context engineering section of the agentic engineering pillars makes this point from a different angle: CLAUDE.md is a briefing document, not a dumping ground. Skill Eval gives you a way to verify that your briefing is actually working.
The minimum viable skill changes. The Anthropic-recommended minimum of five trials implies a certain investment per skill evaluation. This raises the bar for what counts as a skill worth writing at all. If you cannot define a task that exercises the skill in a testable way, you probably cannot define the skill clearly enough for the agent to follow reliably either.
Team-level skill management becomes viable. Right now, skills that multiple engineers touch are a liability. Everyone has their own intuitions about what works, and those intuitions conflict in ways that produce inconsistent agent behavior. With eval scores, you have a shared objective measure. "This change improved the pass^5 score from 60% to 90%" is a statement that does not require anyone to trust your instincts. It is a number.
This connects to the compound engineering idea from the agentic engineering framework: shared infrastructure that accumulates value over time. A skill library with eval coverage is infrastructure. Every new eval makes the library more trustworthy. Every passing eval after a change means the team's collective capability with that skill held steady or improved.
The closing line of Gechev's post is direct: "Skills are becoming a first-class part of how we work with AI agents. As they get more complex and more teams depend on them, testing them stops being optional. Don't ship skills without evals."
That second-to-last sentence is doing a lot of work. As they get more complex and more teams depend on them. Right now, most skills are simple and owned by one person. The cost of not testing them is low. But skill files are getting longer. More workflows are being encoded. More teams are sharing them. The cost of a silent regression in a shared, complex skill is not low. And by the time you notice, you have no idea where it came from.
The time to build the testing habit is before the skills are complex enough that the lack of testing becomes expensive.
FAQ#
What is Skill Eval?#
Skill Eval is a TypeScript framework developed by Minko Gechev that evaluates how well AI agents follow procedural skill files. It runs the agent against a defined task inside a Docker environment, scores the result from 0.0 to 1.0 using deterministic shell scripts or LLM rubrics, and tracks that score across multiple trials to account for nondeterministic behavior.
What is the difference between pass@k and pass^k?#
pass@k measures whether the agent can complete the task on at least one of k trials. It tests for capability. pass^k (pass-all-k) measures whether the agent completes the task on every one of k trials. It tests for reliability. A skill with pass@5 = 100% but pass^5 = 30% means the agent can do the task but is too flaky for production. Use pass@k during development to verify capability, and pass^k before shipping to verify reliability.
Why should AI agent skills have unit tests?#
Agent skills are procedural instructions that govern behavior. Like code, they can be changed in ways that silently break their effectiveness. Unlike code, they have no existing testing infrastructure, so degradation goes undetected. Unit tests for skills provide a concrete score for each version, catch regressions before they reach production, and give teams a shared objective measure rather than subjective impressions of whether the skill is working.
What are deterministic graders vs LLM rubric graders?#
Deterministic graders are shell scripts that check whether a specific, measurable outcome was achieved. Did the file get created? Did the linter pass? LLM rubric graders are prompts that evaluate qualitative aspects of the output that cannot be measured by a script. Did the agent explain clearly? Did it follow style guidelines appropriately? Using both captures whether the agent did the right thing and whether it did it well.
How does Skill Eval integrate with CI?#
Skill Eval includes a GitHub Actions configuration that triggers evaluations on pull requests affecting skill or task files. This means every skill change goes through automated scoring before merging. If the score drops below a threshold, the pull request does not pass. This tightens the feedback loop from discovering regressions in production to catching them before they are committed.
How many trials should you run per evaluation?#
Minko Gechev recommends a minimum of five trials per evaluation, based on Anthropic research. Agent behavior is nondeterministic, meaning the same input can produce different outputs across runs. Five trials gives enough data to separate genuine skill degradation from random variance. For production reliability verification using pass^k, five trials at 100% is a meaningful signal. For faster feedback during development, you might run fewer trials and then run the full suite before merging.
Can Skill Eval work with any AI agent?#
Skill Eval is designed to be provider-agnostic. The sample output in Gechev's post shows a Gemini agent, and the GitHub Actions configuration references both Gemini and Anthropic API keys. The Docker-based environment means the agent runs in isolation with standardized tooling, which should work with any agent that can be invoked from a shell.