I spent three months building agents before I realized I had been reinventing the same wheels, badly. Every new project meant rethinking how steps should connect, how errors should be handled, whether the model should decide its own next action or follow a predetermined path. I was making these decisions by intuition, which is a polite way of saying I was guessing.
The agentic LLM workflow patterns I am going to cover here are a taxonomy for those decisions. They come from Anthropic's Building Effective Agents guide (2024) and a cluster of academic papers, ReAct (2022), Reflexion (2023), ReWOO (2023), and Plan-and-Solve (2023), that gave the field a shared vocabulary. Once you know the names, you start seeing the patterns everywhere. More importantly, you start knowing which one to reach for.
There are nine of them. Some you will use constantly. Some are specialized enough that you will only need them when you hit a specific ceiling. This post covers all nine, with a comparison table and a decision guide at the end.
Table of Contents#
- Why patterns matter more than prompts
- Pattern 1: Prompt Chaining
- Pattern 2: Parallelization
- Pattern 3: Orchestrator-Workers
- Pattern 4: Evaluator-Optimizer
- Pattern 5: Input Router
- Pattern 6: Autonomous Agent Loop
- Pattern 7: Reflexion
- Pattern 8: ReWOO
- Pattern 9: Plan-and-Execute
- Comparison table
- How to choose the right pattern
- When not to use complex patterns
- FAQ
Why Patterns Matter More Than Prompts#
The first instinct when an agent does something wrong is to fix the prompt. Sometimes that is right. But a lot of agent failures are architectural. The model is being asked to do too many things at once, or the task requires iteration that the design does not support, or there is no mechanism to catch errors before they propagate downstream.
Patterns are the architectural answer. They define how model calls connect, how control flows between them, how errors surface, and how results are aggregated. Getting the pattern right is often more valuable than spending another afternoon tuning the prompt.
The nine agentic LLM workflow patterns below are ordered roughly by complexity, starting with the simplest. Most real systems combine two or three of them.
Pattern 1: Prompt Chaining#
The simplest pattern. You call an LLM, take its output, and pass it as input to the next LLM call. Repeat for as many steps as your task requires.
The key insight is that focused steps fail smaller. A model asked to translate a document, then summarize it, then extract action items will do each step better than a model asked to do all three at once. The failure surface for each step is narrower. When something goes wrong, you know which step produced the bad output.
The interesting design decisions live at the gates between steps. Do you validate the output before passing it forward? Can you add a lightweight check that confirms the previous step produced something usable before the next step consumes it? This gate step does not need to be a full model call. It can be a schema check, a length check, a regex match. The goal is catching bad outputs before they corrupt subsequent steps.
The real failure mode for prompt chaining is cascading errors. If step one produces something plausible but subtly wrong, step two inherits that wrongness and builds on it. By step four, the error can be invisible in the final output but deeply embedded in the reasoning. Validating at each gate is the mitigation. It adds calls, but it adds reliability faster than it adds cost.
Prompt chaining pairs naturally with parallelization. When steps are genuinely independent, there is no reason to run them sequentially.
Pattern 2: Parallelization#
Two sub-patterns live under this label, and they solve different problems.
Sectioning divides a large input into chunks, processes all chunks simultaneously with separate model calls, and aggregates the results. The latency argument is obvious. A document that would take 40 seconds processed sequentially takes the same 40 seconds as the longest single chunk when parallelized. The harder part is aggregation. Combining outputs from parallel calls requires its own logic, and that aggregation step is where sectioning systems usually break. It is worth designing the aggregation step before you build the parallel steps, not after.
Voting sends the same input through multiple model calls and selects the output by majority or by confidence score. The reliability argument: nondeterministic models sometimes produce outlier outputs, and voting is a way to catch and discard them. One caveat is that voting becomes less useful when temperature is set low. At low temperature, you are likely to get near-identical outputs from each call, which means the vote has little signal. Voting earns its cost at higher temperatures, where output variance is meaningful.
Both sub-patterns pay off most when the unit cost of individual calls is low and latency matters more than raw token spend.
Pattern 3: Orchestrator-Workers#
This is where things get more interesting. An orchestrator LLM reads the current state of a task, decides what to do next, dispatches a worker LLM or tool to do it, incorporates the result, and repeats. The key difference from prompt chaining is that the sequence is not predetermined. The orchestrator decides at runtime what the next step is, based on what it has seen so far.
Workers should be narrow. The more you constrain a worker's scope, the more reliably it performs within that scope. A worker that does one thing well is better than a worker that does three things adequately. Think of workers like pure functions: given this input, produce this output, no side effects outside the defined task.
The failure mode worth planning for upfront is orchestrator context accumulation. Over a long task, the orchestrator's context window fills with the history of every dispatch and result. Eventually, performance degrades. The orchestrator starts making worse decisions not because the task is harder but because it is drowning in its own history. Context management is not an afterthought here. You need a rolling summary strategy or a structured state object from the beginning.
The Building Production-Ready Multi-Agent Systems post goes deep on orchestrator architecture and the state management patterns that prevent context drift from killing long-running tasks.
Pattern 4: Evaluator-Optimizer#
A generator model produces an output. An evaluator model critiques that output against defined criteria. The generator revises based on the critique. You repeat for a bounded number of rounds.
This sounds simple. The part that determines whether it actually works is the evaluator's criteria. "Is this good?" is not criteria. "Does this response cite at least three specific examples, stay under 200 words, and avoid passive voice?" is criteria. The more precise the evaluator prompt, the more useful its feedback, and the more the generator can act on it.
A few things worth knowing:
The ceiling on iterations should be hard. Two to three rounds is usually right. After that, gains are marginal and you are often in the territory of the generator and evaluator talking past each other.
You do not need a different model for the generator and the evaluator. The same underlying model can perform both roles if the prompts are genuinely separated and the evaluation criteria are concrete. Prompt separation matters more than model separation.
The Five Pillars of Agentic Engineering covers agentic validation as its own pillar, with more on how evaluation fits into the broader discipline of making agent behavior reliable over time.
Pattern 5: Input Router#
Before processing begins, classify the input and send it to the handler best equipped for that type of input. A technical support query goes to a handler with access to documentation. A billing query goes to a handler with access to account data. A general question goes to a generic handler.
The value is captured only if the classification is accurate. A router that misclassifies 20% of inputs destroys half the value of specialization, because those misrouted inputs get handled worse than they would have been by a general handler. Testing the classifier on ambiguous cases is more important than testing it on easy ones. Easy cases classify themselves. Ambiguous cases expose the actual decision boundary.
Routing decisions can carry metadata downstream. When a router classifies an input, it can attach that classification and its confidence score to the payload. The downstream handler can use that metadata to adjust its behavior, which is often more valuable than pure routing.
A hybrid approach works well in practice: rule-based routing for high-confidence cases, model-based routing for ambiguous ones. Rules are cheaper and faster for the inputs you already understand. Model judgment is better for the long tail.
Pattern 6: Autonomous Agent Loop#
The model decides which tool to call next, calls it, observes the result, and decides what to do next. It keeps going until it determines the task is complete, encounters an unrecoverable error, or hits a hard limit.
That last clause is not optional. Three stopping conditions are required:
- A completion signal. The model must have a way to declare the task done.
- An unrecoverable error path. The model must have a way to exit gracefully when it encounters something it cannot handle.
- A hard step count or time limit. Without this, a loop that goes wrong can run forever, consuming tokens and doing damage.
Tool design matters enormously here. A narrow, well-documented tool outperforms a broad one. A tool that does one thing with a clear description of what it does and when to use it will be called correctly more often than a tool with a wide surface area and vague documentation. When you find your agent misusing a tool, the first thing to check is the tool description, not the agent's reasoning.
Context accumulation is the same problem as in orchestrator-workers, and the rolling summary approach is the same mitigation. The agent loop's context grows with every action and observation. Letting it grow without management produces the same late-task degradation.
This is the pattern Claude Code runs. Every time it reads a file, edits code, runs a command, and checks the result, it is executing an autonomous agent loop.
Pattern 7: Reflexion#
Introduced in a 2023 paper by Shinn et al., Reflexion addresses a specific failure mode: the agent that keeps trying the same thing after it fails, with no mechanism to reason about why it failed.
The pattern adds a verbal self-reflection step. After a failed attempt, the model writes out an explanation of why it failed, what specifically went wrong, and what it would do differently. That reflection is stored and passed as additional context on the next attempt.
The paper's benchmark result: HumanEval pass rate of 91% with Reflexion, compared to an 80% baseline. The mechanism makes sense. Writing out failure reasons is not just logging. It is a form of deliberate reasoning that forces the model to be specific about what went wrong rather than just retrying with unstructured hope.
Practical ceiling: three rounds. Beyond that, the reflections start to recycle the same observations and the signal degrades. The reflection quality also depends on the model having enough information to reason about its failure. If the failure is due to a tool returning unhelpful output, the model cannot reflect its way past an information gap.
Pattern 8: ReWOO#
ReWOO stands for Reasoning Without Observation. The idea is to plan all tool calls upfront, without seeing intermediate results, then execute the full plan in batch.
The standard approach (ReAct) interleaves reasoning and tool calls. The model reasons, calls a tool, observes the result, reasons again, calls another tool, and so on. ReWOO separates planning from execution. The model produces a complete plan of tool calls as a single step, then executes them all without the reasoning-observation interleaving.
The 2023 paper by Binfeng Xu et al. reports approximately 67% token savings compared to standard ReAct. The saving comes from eliminating the per-step reasoning cycles that interleaved approaches require.
The tradeoff is adaptability. When intermediate results are surprising, ReWOO cannot adjust mid-execution. The plan was made without seeing any results. If step three returns something that changes what step four should do, a ReWOO agent cannot respond to that. ReAct can.
ReWOO works best when the tool call sequence is predictable from the task description alone. If you can look at a task and know with reasonable confidence what steps it requires, ReWOO can execute those steps much more efficiently. If the task requires discovering what to do next based on what you find along the way, stick with ReAct.
Pattern 9: Plan-and-Execute#
An explicit planning phase produces an inspectable artifact, typically a numbered task list. An execution phase works through the plan, with optional replanning when a step fails.
Two distinctions worth being clear about:
Versus ReWOO: Plan-and-Execute allows replanning when execution steps fail. ReWOO does not. The plan can change in response to what execution discovers.
Versus the autonomous agent loop: the plan is an inspectable artifact before execution begins. In an autonomous loop, the model decides actions one at a time. In Plan-and-Execute, you can see the full plan before any action is taken. This enables human review and approval before execution starts, which matters enormously for tasks with real-world consequences.
The cost is a minimum of two model calls, one to plan and at least one to execute. For short tasks, that overhead is not worth it. For tasks with more than five steps, or tasks where human approval before execution is valuable, Plan-and-Execute is the right choice. The inspectable plan is not just a nice-to-have. It is the mechanism that puts a human in the loop without requiring the human to watch every action in real time.
The long-running AI agent harness post covers how to build the execution scaffolding that makes Plan-and-Execute reliable in production, particularly around state persistence and recovery from partial execution failures.
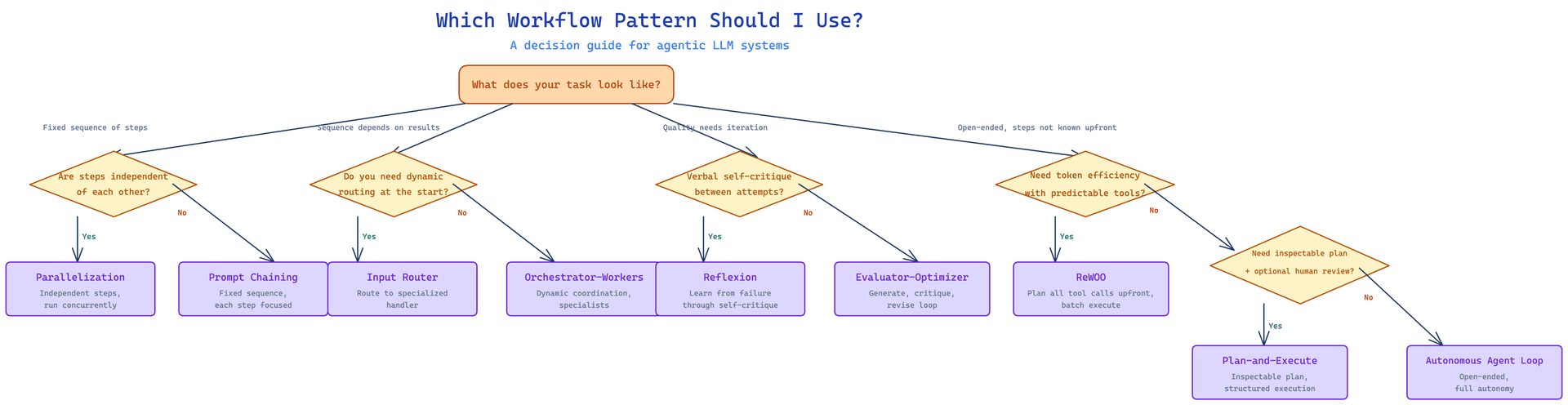
Which Pattern Should I Use?#
The diagram below maps the nine patterns to a decision tree. Start at the top and follow the branches based on what your task looks like.
Comparison Table#
| Pattern | LLM Calls | Adaptability | Best For |
|---|---|---|---|
| Prompt Chaining | N (fixed) | Low | Fixed multi-step pipelines |
| Parallelization | N (parallel) | Low | Throughput, voting across outputs |
| Orchestrator-Workers | Dynamic | High | Tasks requiring dynamic dispatch |
| Evaluator-Optimizer | N (iterative) | Medium | Output quality improvement |
| Input Router | 1 + handler | Low | Specialized handling by input type |
| Autonomous Agent Loop | Dynamic | Very High | Open-ended tasks |
| Reflexion | N (iterative) | Medium | Failure-driven learning |
| ReWOO | N (batch) | Very Low | Token efficiency, predictable sequences |
| Plan-and-Execute | 2+ | Medium | Multi-step tasks, human-in-the-loop |
How to Choose the Right Pattern#
Start with the simplest pattern that fits the task. Most people reach for complex patterns before they need them.
Here is a prose decision guide:
If your task has a fixed sequence of steps where each step is independent of what prior steps actually returned, start with prompt chaining. Add gate validation between steps.
If those steps are genuinely independent and can run at the same time, add parallelization.
If the sequence of steps depends on what results come back as the task progresses, you need orchestrator-workers. The orchestrator reads state and decides what comes next.
If quality needs to improve through iteration and you can define concrete evaluation criteria, add evaluator-optimizer on top of your generator.
If your inputs fall into distinct categories that each require specialist handling, add an input router before the main processing.
If the task is open-ended and you genuinely cannot specify the steps upfront, use an autonomous agent loop with hard stopping conditions.
If the agent keeps failing in similar ways and you need it to reason about those failures explicitly, add Reflexion.
If the tool sequence is predictable and token cost matters, replace ReAct with ReWOO.
If the task has more than five steps and human review before execution would reduce risk, use Plan-and-Execute.
When Not to Use Complex Patterns#
The patterns described above exist to solve real problems. They are not features to add because they sound sophisticated.
A task that works with a single model call does not need prompt chaining. Splitting it into five steps adds latency, adds cost, adds surface area for bugs, and gains nothing.
Orchestrator-workers adds significant design and operational complexity. The orchestrator needs careful context management. Workers need to be designed as narrow, focused units. Monitoring and debugging a multi-agent system is harder than monitoring a pipeline. Do not build orchestrator-workers because the task sounds complicated. Build it because you have hit the actual ceiling of simpler patterns and you have identified specifically what that ceiling is.
Evaluator-optimizer adds at least one extra model call per generation cycle. If your first-pass outputs are already good enough for the use case, the additional cost is waste.
Plan-and-Execute has a minimum overhead of two model calls. For tasks that are short or well-understood, that overhead is not justified.
The right place to start is a single well-designed prompt. When you hit a failure you cannot solve by improving the prompt, look at whether the failure is architectural. If it is, find the simplest pattern that addresses the specific architectural problem. Add complexity only when you have a real problem that simpler approaches have already failed to solve.
The agentic apps build and run cost post covers the economic reasoning behind this, particularly why adding complexity too early compounds run costs in ways that become visible only after you are already in production.
These patterns are also the building blocks behind the agent workflow templates on the /workflows page, if you want to see them in executable form.
FAQ#
What are agentic LLM workflow patterns?#
Agentic LLM workflow patterns are named architectural patterns that define how model calls connect, how control flows between them, and how tasks are decomposed across multiple steps or agents. They come from Anthropic's Building Effective Agents guide (2024) and published research including ReAct (2022), Reflexion (2023), ReWOO (2023), and Plan-and-Solve (2023). Knowing these patterns helps you make architectural decisions by analogy rather than from scratch.
What is the difference between prompt chaining and an autonomous agent loop?#
Prompt chaining follows a predetermined sequence of model calls. The order and number of steps is defined before the task runs. An autonomous agent loop lets the model decide at runtime what action to take next, based on what it has observed so far. Prompt chaining is predictable and easier to debug. Autonomous loops are more flexible for open-ended tasks.
When should I use ReWOO instead of ReAct?#
Use ReWOO when the sequence of tool calls required for a task is predictable from the task description alone, and when token cost is a real concern. ReWOO batches all tool calls after a single planning step, which Binfeng Xu et al. showed saves roughly 67% of tokens compared to standard ReAct. Use ReAct when intermediate results might change what steps you need to take, since ReWOO cannot adapt mid-execution.
How many iterations should an evaluator-optimizer loop run?#
Two to three iterations is usually the right ceiling. Gains after three rounds are typically marginal, and the generator and evaluator can start producing circular feedback rather than genuine improvement. Set the hard limit before you deploy, not after you notice runaway costs.
Is Reflexion the same as just retrying a failed task?#
No. A plain retry sends the same input again and hopes for a different output. Reflexion adds a verbal self-reflection step. After a failure, the model writes out an explanation of what went wrong and what it should do differently. That reflection is included in the context of the next attempt. The mechanism makes the retry genuinely informed by the prior failure rather than statistically independent of it.
Can I combine multiple patterns in one system?#
Yes, and most real systems do. Orchestrator-workers is often combined with prompt chaining at the worker level. An autonomous agent loop can include Reflexion for failure handling. Plan-and-Execute can use parallelization during the execution phase for independent steps. The patterns are composable. The goal is to use the simplest combination that solves the actual problems your system faces.
What is the source taxonomy for these patterns?#
The nine patterns in this post are grounded in two sources. Anthropic's Building Effective Agents (2024) describes prompt chaining, parallelization, orchestrator-workers, evaluator-optimizer, input router, and the autonomous agent loop. The ReAct paper (Yao et al., 2022) established the interleaved reasoning-action pattern. The Reflexion paper (Shinn et al., 2023), the ReWOO paper (Xu et al., 2023), and the Plan-and-Solve paper (Wang et al., 2023) each introduced the patterns they are named after, with empirical results comparing them to baselines.