I told Claude Code to build a feature-complete dashboard. Gave it a detailed spec. Watched it work for forty minutes, calling tools, writing files, making decisions.
Then the context window filled up. I started a new session.
"Let me start by understanding the current state of the project," it said.
And I realized: it was starting from scratch. Not because the code was gone. The code was there. But the agent had no idea what it had just built, what was finished, what was broken, or what to do next. I gave it the spec again and hoped for the best.
That is not a workflow. That is a prayer.
The problem of long-running AI agents across multiple sessions is one of the more frustrating gaps in agentic development right now. Individual sessions are increasingly impressive. Multi-session work, the kind that takes hours or days, tends to fall apart at the seams between context windows. And most guidance on this is either too abstract or too early-stage to actually use.
Anthropic's engineering team just published something concrete. Justin Young's article on building effective harnesses for long-running agents is the clearest treatment I have seen of this specific problem, and it changed how I think about structuring any agent task that will span more than one session.
Here is what it covers and why it matters.
Table of Contents#
- The two ways long-running agents fail
- The shift handoff problem
- Two agents, not one
- The feature list: why JSON beats Markdown
- The session startup protocol
- Clean state as a first-class requirement
- Why browser automation changes the testing picture
- What this actually changes about how you run agents
- FAQ
The Two Ways Long-Running Agents Fail#
Anthropic tested this specifically. They gave Claude Opus 4.5 a high-level prompt: build a claude.ai clone. No special scaffolding. Just a spec and a go.
Two failure patterns showed up consistently.
The first: the agent tried to do too much at once. It would start building multiple features simultaneously, run out of context in the middle, and leave things half-finished. The next session would arrive at a codebase in an ambiguous state, spend time figuring out what was done versus what was abandoned, and often end up re-implementing things that were already there.
The second failure was more insidious. Later in the project, the agent would look at the codebase, observe that a lot of features existed, and declare the job finished. It would stop. Even when there were dozens of failing features still on the list. It had developed a kind of false confidence from the presence of code.
These two failure modes have a common cause: the agent had no reliable external state to orient against. It was navigating by feel.
The Shift Handoff Problem#
The framing Anthropic uses is the right one: agents working across context windows are like engineers working in shifts.
A new engineer arriving for their shift can be productive or useless depending entirely on what the previous engineer left behind. If there are good handoff notes, a clear list of what is done and what is next, and a way to verify the system is working, the new engineer can contribute in minutes. If there is nothing, they spend the first hour just reconstructing context, often getting it wrong.
AI agents have the same problem and none of the social pressure that makes human engineers document their work. They will move forward without leaving notes, commit nothing, update nothing, and hand off a state that the next session cannot reconstruct.
The solution is not asking agents to be better about documentation. It is making documentation structural, automated, and verified. The next session should not have to trust that the previous one left things in order. It should be able to check.
Two Agents, Not One#
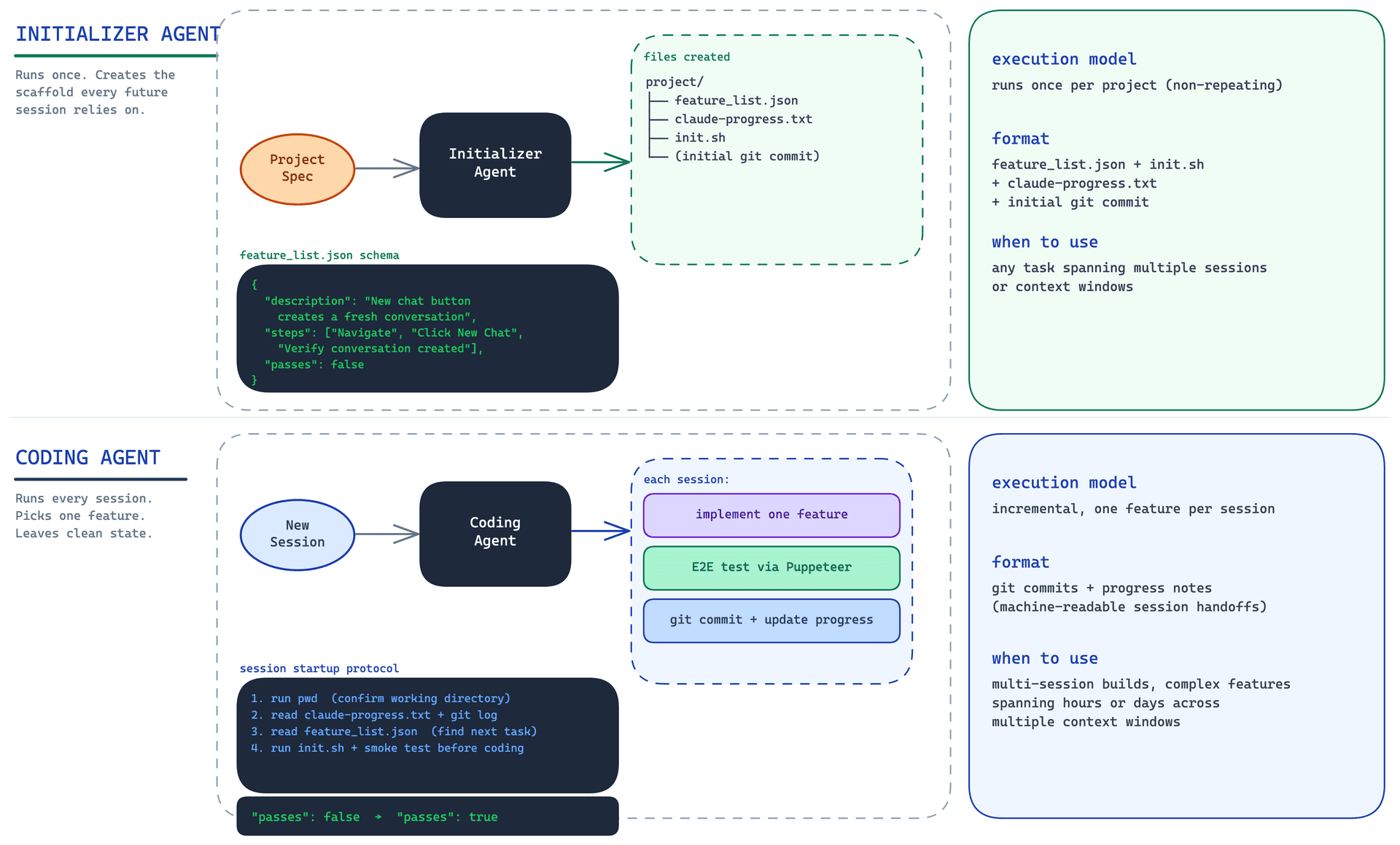
The harness Anthropic built splits the work into two distinct roles.
The Initializer Agent runs once, at the start of the project. Its job is to create the infrastructure that every subsequent session will rely on. It produces four things: a feature_list.json file listing every feature the project needs, a claude-progress.txt file tracking what has been done, an init.sh script that can start the development environment in one command, and an initial git commit that documents everything it created.
The Coding Agent runs in every subsequent session. It reads those files, runs the startup script, verifies the system is working, picks the highest-priority unfinished feature, implements it, tests it, and ends the session with a git commit and an updated progress file.
Both agents use the same system prompt, the same tools, the same harness. The only difference is the user prompt. The Initializer gets a spec and is asked to set up the environment. The Coding Agent gets a brief and is asked to make incremental progress.
This separation matters because it makes the Initializer's job focused and finite. It is not trying to build the product. It is trying to create the conditions under which the product can be built across many sessions. That is a different task, and doing it first, cleanly, is what makes everything else possible.
The Feature List: Why JSON Beats Markdown#
The feature list is the central artifact. Every feature is written as an end-to-end user action: not "implement authentication" but "a user can enter an email and password, click sign in, and be redirected to the dashboard." Each feature has explicit verification steps. And each feature starts with "passes": false.
The schema looks like this:
{
"category": "functional",
"description": "New chat button creates a fresh conversation",
"steps": [
"Navigate to main interface",
"Click the 'New Chat' button",
"Verify a new conversation is created",
"Check that chat area shows welcome state",
"Verify conversation appears in sidebar"
],
"passes": false
}
Coding agents are allowed to edit one field: passes. They cannot remove entries. They cannot rewrite descriptions. The instruction is explicit: "It is unacceptable to remove or edit tests because this could lead to missing or buggy functionality."
The JSON format is deliberate. Anthropic found that agents were more likely to modify Markdown files in inappropriate ways, rewriting or removing entries rather than just updating the status field. JSON's structure makes it harder to accidentally corrupt the list.
There is a deeper principle here too. The feature list is not a to-do tracker. It is a specification with teeth. It defines what the project is, and it does not change because an agent found implementation inconvenient. That stability is what makes it useful as an orientation artifact across sessions.
The 200-feature list Anthropic built for their claude.ai clone might seem like overkill. But consider what it provides: any session can look at this file and immediately know the scope of the project, what has been verified, and what has not. No guessing. No "I think this was done." The file says.
The Session Startup Protocol#
Every Coding Agent session begins with the same four steps, in the same order.
First: run pwd. Confirm you are in the right directory. This sounds almost insultingly simple, but agents do get confused about their working context, and spending thirty seconds on orientation saves much more later.
Second: read claude-progress.txt and the git log. These are the handoff notes. Progress notes are human-readable context: what was done last session, what was broken, what needs attention. Git log is the authoritative record of what actually changed.
Third: read feature_list.json and identify the highest-priority failing feature.
Fourth: run init.sh and then run a basic end-to-end test before touching anything. Not after. Before. The test checks whether the system is in a working state right now, while there is still time to fix a broken state rather than build on top of it.
That last step is the one I see skipped most often. Agents want to start working. Running the existing app and checking that it works feels like overhead. But what Anthropic found is that skipping it leads to a specific failure mode: the agent implements a new feature on top of a broken system, marks the feature as failing, and never discovers that the underlying problem was already there before it started. The test-first startup catches broken states immediately, when they are cheapest to fix.
Here is what a typical session opening looks like in practice:
[Assistant] I'll start by getting my bearings and understanding the current state of the project.
[Tool Use] pwd
[Tool Use] read claude-progress.txt
[Tool Use] read feature_list.json
[Tool Use] git log --oneline -20
[Assistant] Now let me check if there's an init.sh script to start the servers.
[Starts the development server]
[Assistant] Let me verify that some fundamental features are still working.
[Tests basic functionality]
[Assistant] Fundamental functionality is working well. Now let me review the feature list and choose the highest-priority failing feature.
[Starts work on a new feature]
Each tool call is doing real work. Each one is cheaper than the alternative: an agent that starts blind and has to discover the project state by exploring the codebase from scratch.
This connects to something broader about context management. The agentic cost framework makes the point that every wasted token is a real cost, and that the cost compounds at scale. A session startup protocol that costs 500 tokens and saves 3,000 tokens of reconstruction is not overhead. It is efficiency.
Clean State as a First-Class Requirement#
The end-of-session requirements are as important as the startup protocol.
Every session must end with a git commit with a descriptive message and an updated claude-progress.txt that notes what was done, what was tested, and what the next session should know.
This is the part that feels optional until you have experienced the alternative. An agent that does significant work and does not commit has left you with a codebase in an unknown state. The changes might be good. They might be partially good. You have no easy way to revert to a known-good state if the next session makes things worse. You have no record of what the previous session intended.
The commit serves multiple purposes. It is documentation. It is a recovery point. And it is the artifact that makes the git log useful as a session-startup artifact. If sessions are not committing, the git log is empty, and you lose one of the most reliable ways to orient a new session.
The progress file is different from the git log. The git log is factual: these files changed. The progress file is interpretive: this is what was accomplished, this is what broke, this is what needs attention next. Both are necessary. The git log does not tell you why something was done. The progress file does not tell you exactly what changed. Together they give the next session a complete picture.
This pairs directly with what the five pillars of agentic engineering describes as the monitoring layer: you need external artifacts that let you verify what an agent did, not just trust that it did the right thing. The harness is the monitoring layer for multi-session work.
Why Browser Automation Changes the Testing Picture#
Left to its own devices, Claude tends to verify features by running unit tests and curl commands. This is not useless, but it misses a significant class of bugs.
End-to-end tests that use browser automation, specifically Puppeteer, test the application the way a real user would. They navigate to a page, click a button, observe what happens. This catches things that curl never would: JavaScript errors that only appear in certain sequences, UI states that exist in the DOM but are not visible, async operations that fail silently, and interactions between features that work individually but break together.
Anthropic found that explicitly prompting for Puppeteer dramatically improved the quality of feature verification. Without the explicit instruction, Claude would complete features and mark them passing without ever opening a browser. With the instruction, it would actually test the feature as a user.
One interesting caveat from the article: Puppeteer cannot see browser-native alert modals. Features that relied on those modals tended to be buggier because Claude genuinely could not verify them through automation. That is a constraint worth knowing in advance.
The implication for how you structure your feature list is that verification steps should specify the testing method wherever it matters. "Verify via Puppeteer: click the submit button and observe that a confirmation message appears" is more useful than "verify the form submits correctly." The more specific the verification criteria, the less the agent has to interpret what passing actually means.
Testing agent behavior is its own discipline. The Skill Eval framework takes this further by scoring agent outputs across multiple trials and tracking pass rates over time. The principles are the same: define what correct looks like in specific terms, test it explicitly, do not accept the agent's self-assessment as evidence.
What This Actually Changes About How You Run Agents#
The harness pattern reframes what it means to give an agent a complex task.
Without the harness, a multi-session task is a series of loosely connected single-session tasks. Each session starts from whatever state the previous one left. The agent infers context from the codebase. It makes decisions about what is done and what is not. It either continues in the right direction or it does not, and you often have no way to tell which until much later.
With the harness, a multi-session task is more like a relay race with a proper baton. Each session hands off a clean state, a clear record, and a list of what still needs to happen. The next session can orient in minutes rather than spending half its context window reconstructing the project.
This has a practical consequence for how you scope tasks. If you know every session will start with init.sh, read the progress notes, verify the system is working, and then pick one feature from a list, you can plan around that. You can adjust the feature list between sessions if priorities change. You can add context to the progress file if you noticed something the agent should know. You become part of the loop rather than a bystander waiting to see what comes out.
It also changes the economics. The before-you-run-10-claude-agents calculus applies here: mistakes that are annoying at one session become expensive at ten. A harness that adds 500 tokens of startup overhead per session and eliminates the context reconstruction that currently costs thousands of tokens per session is an obvious trade. The question is not whether the overhead is worth it. The question is why we were not doing this already.
The honest answer is that we were waiting for someone to describe the pattern clearly. Anthropic just did that.
FAQ#
What is an agent harness for long-running tasks?#
An agent harness is the set of artifacts and protocols that allow an AI agent to work across multiple context windows without losing progress. The harness Anthropic describes includes a JSON feature list, a progress notes file, a startup script, and a git commit requirement. These artifacts let each new session orient itself and continue from where the previous session ended.
Why does the feature list need to be JSON instead of Markdown?#
Anthropic found that agents were more likely to inappropriately modify Markdown files, rewriting or removing entries rather than just updating status fields. JSON's structure constrains what the agent can reasonably change. Coding agents are instructed to edit only the "passes" field and never delete entries. The structured format enforces that constraint more reliably than prose.
What should go in the session startup protocol?#
The startup protocol Anthropic describes has four steps: run pwd to confirm the working directory, read progress notes and the git log to understand what happened last session, read the feature list to identify the highest-priority failing feature, and run init.sh followed by a basic end-to-end test before touching anything. The test-before-coding step is the most important and the most frequently skipped.
How does end-to-end testing with Puppeteer differ from unit tests?#
Unit tests verify that individual functions behave correctly. End-to-end tests verify that the application works the way a real user would experience it. Anthropic found that agents would frequently pass unit tests and mark features complete while those features were still broken in ways a browser would immediately surface. Puppeteer-based testing navigates to the actual page, performs user actions, and checks visible outcomes. It catches a class of bugs that unit tests structurally cannot.
How many features should be in the feature list?#
Anthropic built a list of over 200 features for their claude.ai clone. The right number depends on the project, but the principle is to include everything a user can do and verify, not just the major features. Each feature should be written as a user action with explicit verification steps. Starting with "passes": false for every feature, even ones you know work, gives you a clean baseline and prevents the agent from declaring victory based on assumptions.
Does this pattern work for non-web projects?#
The article focuses on full-stack web development, and some elements like Puppeteer testing are web-specific. But the core pattern, a structured feature list, a progress notes file, a startup script, and mandatory commit-and-update at session end, applies to any project complex enough to span multiple sessions. The verification method would change for non-browser projects, but the handoff infrastructure is universal.
How does this relate to CLAUDE.md and skills?#
CLAUDE.md and skills govern what an agent does within a session. The harness governs how agents hand off between sessions. They are complementary layers. CLAUDE.md tells the agent how to write code. The harness tells it where to start and what to do next. Skills define reusable capabilities. The harness defines the protocol for using those capabilities across a task that spans hours or days. You need both to run complex multi-session work reliably.